MCP (KI)
Verbinden Sie Claude, ChatGPT, Cursor und andere KI-Assistenten direkt mit Ihren QUESTIONSTAR-Umfragen. Erstellen Sie Zusammenfassungen, berechnen Sie Kreuztabellen, generieren Sie individuelle Auswertungen — über Prompts in natürlicher Sprache, auf Ihren eigenen, aktuellen Umfragedaten.
Was ist der QUESTIONSTAR MCP — in einer Minute
Das Model Context Protocol (MCP) ist ein offener Standard, der KI-Assistenten mit Live-Daten und Werkzeugen verbindet. Stellen Sie es sich vor wie USB-C für KI: jeder MCP-kompatible KI-Client (Claude Desktop, ChatGPT, Cursor, Zed und weitere) kann sich an jeden MCP-kompatiblen Server anschließen und nutzen, was dieser anbietet — Lesezugriff, Schreibzugriff, strukturierte Abfragen — ohne dass jemand maßgeschneiderte Integrationen programmieren muss.
Der QUESTIONSTAR-MCP-Server stellt diesen KI-Clients Ihre Umfragen, Antworten, Befragten und Exporte zur Verfügung. Wenn Sie der KI eine Frage zu Ihren Daten stellen, stützt sie sich nicht auf Trainingswissen oder eine veraltete Kopie — sie ruft den QUESTIONSTAR-MCP auf, liest die Live-Daten und antwortet basierend auf dem, was sie tatsächlich findet.
Anschaulich gesagt: Ohne MCP ist eine Unterhaltung mit einer KI über Ihre Umfrage so, als würden Sie jemandem ein Foto am Telefon beschreiben — er bildet sich eine Vorstellung aus Ihrer Beschreibung.
Mit MCP geben Sie der KI das Foto in die Hand. Sie schaut direkt darauf. Die Antworten basieren auf den tatsächlichen Daten — nicht auf einer Beschreibung davon.
Ein Praxis-Beispiel: vorher und nachher
Stellen Sie sich vor, Sie führen monatlich eine Kundenzufriedenheits-Umfrage durch. Jeden Monat erstellen Sie eine Zusammenfassung für das Management-Team.
Vor MCP — der typische Ablauf
Die eingebaute Analytik von QUESTIONSTAR übernimmt den Großteil der Arbeit: Diagramme und Verteilungen, Kreuztabellen, Word Cloud und TF-IDF auf offene Antworten, sogar fertige Word/PDF-Exporte mit Ihren eigenen Notizen. Der "Vor MCP"-Ablauf hat also nichts mit dem Berechnen zu tun — das übernimmt QS. Es geht um die menschliche Arbeit, die über der Analytik liegt:
Umfrage in QUESTIONSTAR öffnen. Blick in den Bericht — Zahlen, Diagramme und die Word Cloud / TF-IDF für offene Fragen sind direkt da.
50–200 offene Antworten selbst lesen, um ein Bild zu bekommen, was die Befragten wirklich sagen — die Word Cloud gibt Hinweise auf Themen, interpretieren müssen Sie selbst.
Vergleich mit der Vorperiode per Augenmaß — die Zahlen vom Vormonat holen, neben die aktuellen legen, Deltas im Kopf festhalten.
Quervergleiche suchen, die im Standardbericht nicht vorgesehen sind — "Konzentriert sich das Cluster der negativen Kommentare auf eine bestimmte demographische Gruppe?" oder "Bewerten Befragte, die sich über den Preis beschweren, auch den Support schlechter?" Meist ein manueller Filter-Durchgang.
Den narrativen Text schreiben. QS exportiert Ihre Diagramme und Notizen nach Word; die meisten schreiben den Fließtext trotzdem nochmal um — für das jeweilige Publikum (kurze Geschäftsführungs-Zusammenfassung vs. 5-Punkte-Team-Digest vs. ausführliches Board-Memo).
Feinschliff, abschicken.
Realistische Dauer: 30–60 Minuten pro wiederkehrendem Bericht. Der Großteil davon ist Interpretation, narratives Schreiben und Quervergleiche, die der Standardbericht nicht vorhersehen kann.
Mit MCP — dieselbe Aufgabe
Sie öffnen Ihren KI-Client und tippen:
Vergleiche die Kundenzufriedenheit dieses Monats mit dem Vormonat. Zieh die wiederkehrenden Themen aus den offenen Antworten. Markiere demographische Muster bei negativen Kommentaren. Schreib eine einseitige Executive Summary fürs Management-Meeting — 3 Stärken, 3 Sorgen, 2-3 wörtliche Zitate.
Die KI liest die Daten live über den MCP, berechnet das Periodendelta, klassifiziert die Stimmung der Kommentare, findet den Quervergleich zwischen negativen Kommentaren und Demographie der Befragten (genau die Art Erkenntnis, die ein fester Berichtsentwurf nicht automatisch hervorbringt) und entwirft den Text.
Realistische Dauer: 3–5 Minuten.
Die eigentliche Pointe ist nicht die Zeitersparnis bei dieser einen Aufgabe — sondern dass Sie nach der einmaligen Einrichtung jederzeit nach Interpretationen, Zusammenfassungen in mehreren Sprachen, nicht-standardisierten Perioden- oder Segmentvergleichen, Korrelationen zwischen Textantworten und Demographie fragen können — alles, was die Standardvorlage nicht vorsieht. Jedes davon war früher eigene Handarbeit; heute ist es ein Satz.
In drei Schritten loslegen
Die Einrichtung dauert beim ersten Mal etwa 5 Minuten. Sie brauchen (a) einen API-Token aus QUESTIONSTAR und (b) einen KI-Client, der MCP unterstützt. Beides ist unkompliziert.
Schritt 1 — QUESTIONSTAR-API-Token erstellen
In QUESTIONSTAR authentifiziert der API-Token die MCP-Verbindung. Ein Token pro KI-Client ist die sicherste Variante — so können Sie den Zugriff eines einzelnen Clients entziehen, ohne andere zu beeinträchtigen.
Klicken Sie in QUESTIONSTAR oben rechts auf Ihren Namen und wählen Sie Integrationen.
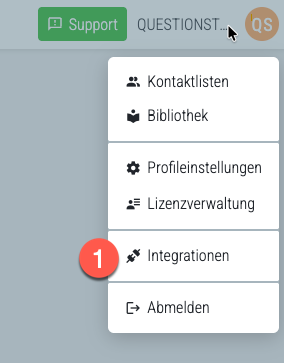
Im linken Navigationsmenü wählen Sie API-Tokens.
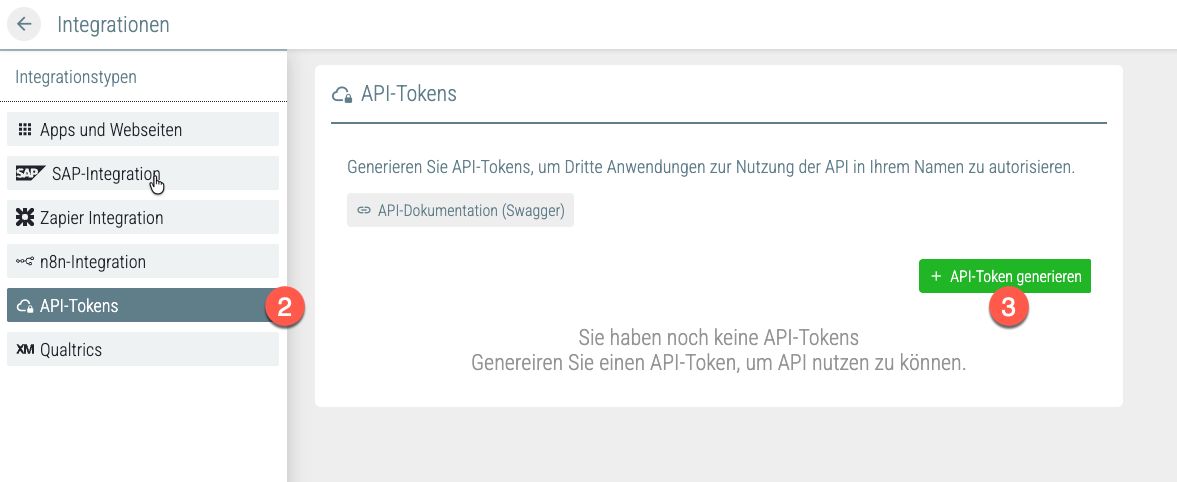
Klicken Sie auf + API-Token generieren.
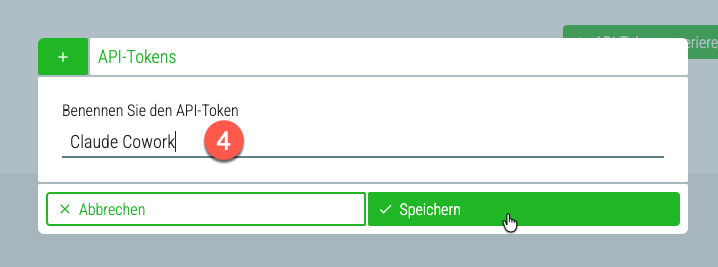
Vergeben Sie einen Namen (z. B. „Claude Desktop“ oder „ChatGPT Work“) und klicken Sie auf Speichern.
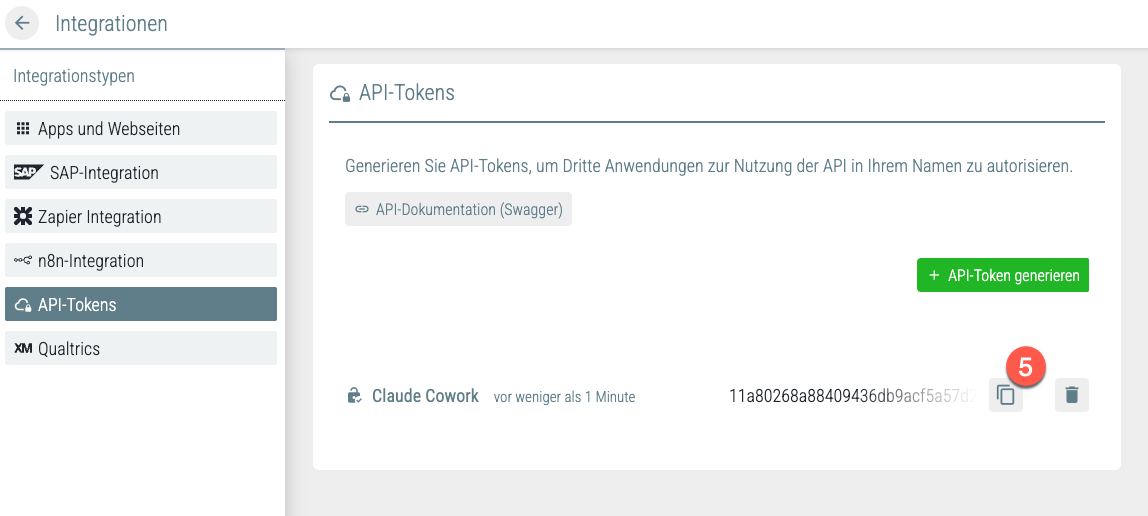
Kopieren Sie den Token sofort über die Kopier-Schaltfläche daneben. Sie fügen ihn in Schritt 2 in Ihren KI-Client ein.
Behandeln Sie den API-Token wie ein Passwort. Jeder, der ihn hat, kann unter Ihrem Namen Umfragedaten lesen und schreiben. Speichern Sie ihn in den sicheren Einstellungen Ihres KI-Clients — nie in Klartext-Code, Chat-Verläufen, Screenshots oder geteilten Dokumenten.
Wenn ein Token kompromittiert wurde: widerrufen Sie ihn auf derselben Seite Integrationen → API-Tokens (Mülleimer-Symbol). Alte Tokens werden sofort ungültig. Erstellen Sie einen neuen und fügen Sie ihn in Ihren KI-Client ein.
Auf diese Seite können Sie jederzeit zurückkehren, um vorhandene Tokens einzusehen, zu widerrufen oder neue zu erstellen.
Schritt 2 — KI-Client mit dem MCP verbinden
Die MCP-Server-URLs:
https://mcp.questionstar.de/mcp— für QUESTIONSTAR-DE-Kontenhttps://mcp.questionstar.com/mcp— für QUESTIONSTAR-COM-Konten
Sie tragen diese URL zusammen mit Ihrem API-Token (als Bearer-Credential) in Ihren KI-Client ein. Die Einrichtungsschritte variieren leicht je nach Client — die vier häufigsten finden Sie unten.
Claude Desktop
Öffnen Sie Claude Desktop, dann Settings → Connectors → Add custom connector. Tragen Sie ein:
- Name:
QUESTIONSTAR(oder ein beliebiger Name) - URL:
https://mcp.questionstar.de/mcp - Auth:
Bearer IHR_API_TOKEN(Token aus Schritt 1 einfügen, davorBearergefolgt von einem Leerzeichen)
Klicken Sie auf Add. Der Connector erscheint in Ihrer Tool-Liste. Claude fragt standardmäßig vor jedem Tool-Aufruf um Erlaubnis — Sie können einzelne Aufrufe erlauben, alle innerhalb eines Chats oder dauerhaft.
Manche Claude-Desktop-Versionen nutzen statt der Oberfläche eine JSON-Konfigurationsdatei (claude_desktop_config.json). Die äquivalente Konfiguration:
{
"mcpServers": {
"questionstar": {
"url": "https://mcp.questionstar.de/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_TOKEN"
}
}
}
}ChatGPT (Custom Connector)
ChatGPT unterstützt MCP über die Custom-Connector-Funktion in den kostenpflichtigen Tarifen (Plus, Team, Business, Enterprise). In ChatGPT gehen Sie auf Settings → Connectors → Add custom connector und tragen dieselbe URL und denselben Bearer-Token ein. ChatGPT verhandelt anschließend die Tool-Liste mit dem MCP-Server und zeigt die QUESTIONSTAR-Tools in der Modellauswahl an.
Cursor, Zed und andere MCP-kompatible Clients
Die meisten modernen KI-gestützten Editoren und Chat-Clients unterstützen inzwischen MCP. Suchen Sie in den Einstellungen nach „MCP servers“, „Custom integrations“ oder „Custom tools“. Die Konfiguration ist immer dieselbe: URL + Bearer-Token. Die Oberfläche variiert, die einzutragenden Werte nicht.
Bald verfügbar — OAuth. Ein OAuth-Login mit einem Klick ist in Entwicklung. Sobald es verfügbar ist, autorisieren Sie KI-Clients ohne Tokens herumzukopieren — so wie Sie heute Drittanbieter-Apps mit Google oder GitHub verbinden.
Bis dahin ist der oben beschriebene API-Token-Weg der unterstützte Pfad. Bestehende API-Tokens funktionieren auch nach dem OAuth-Release weiter — kein erzwungener Wechsel.
Schritt 3 — Den ersten Prompt ausprobieren
Sobald Ihr Client verbunden ist, öffnen Sie einen neuen Chat und probieren Sie Folgendes:
Welche meiner QUESTIONSTAR-Umfragen laufen aktuell?
Die KI ruft list_surveys auf, filtert nach Status und zeigt Ihnen eine übersichtliche Liste. Beim ersten Mal fragt Ihr Client um Erlaubnis für den Tool-Aufruf — klicken Sie auf Allow. Damit haben Sie eine funktionierende MCP-Integration. Alles Weitere baut darauf auf.
Was der MCP kann — ein Überblick
Der QUESTIONSTAR-MCP stellt derzeit über 20 Tools bereit. Sie müssen sich keine Tool-Namen merken — die KI wählt das passende für Ihre Anfrage. Wichtig ist nur zu wissen, welche Art Fragen Sie überhaupt stellen können. Unten finden Sie eine thematisch gegliederte Übersicht mit ein bis zwei echten Prompts pro Themenbereich und einer Beschreibung, was dabei passiert.
Welche Umfragen haben Sie, und wie sind sie aufgebaut?
Verwendete Tools: list_surveys, get_survey, get_survey_result_items
Beispiel-Prompt:
Liste meine Umfragen auf und sag mir, welche in den letzten 7 Tagen neue Antworten bekommen haben.
Was die KI tut: ruft list_surveys auf, um alle Umfragen zu holen, dann get_survey_last_response pro Umfrage, um das letzte Antwortdatum zu prüfen, filtert auf die letzten 7 Tage und zeigt das Ergebnis als kurze Tabelle. Bei 50 Umfragen dauert das ein paar Sekunden — manuell durch das Dashboard klicken würde Sie 5 Minuten kosten.
Noch ein Beispiel:
Öffne meine Umfrage Kundenzufriedenheit und sag mir, welche Fragen darin enthalten sind.
Was die KI tut: ruft list_surveys auf, um die Umfrage anhand des Namens zu finden, dann get_survey mit dem Umfrage-Code, um das Schema zu laden. Gibt eine nummerierte Liste der Fragen mit Typ (Radio, Text, Matrix usw.) und Antwortoptionen zurück.
Praktisch vor jeder analytischen Anfrage — so kann die KI ihre späteren Antworten am tatsächlichen Schema verankern, nicht an einer Vermutung. Funktioniert auch gut, um sich selbst zu erinnern, was in einer Umfrage steckt, die Sie monatelang nicht angesehen haben.
Tatsächliche Antworten lesen
Verwendete Tools: get_result_cases, get_result_case, get_result_case_complete
Beispiel-Prompt:
Zeig mir die 5 letzten Antworten zu meiner Mitarbeiterbefragung. Pro Antwort die Bewertungsfragen und den offenen Kommentar.
Was die KI tut: findet die Umfrage, holt die letzten Cases über get_result_cases, lädt den vollständigen Antwortsatz pro Case über get_result_case_complete und zeigt das Ganze als kompakte Tabelle. Die KI lässt Metadaten (Zeitstempel, technische IDs) automatisch weg, sofern Sie nicht explizit danach fragen.
Noch ein Beispiel:
Finde alle Antworten, bei denen die Zufriedenheitsbewertung 1 oder 2 war, und füge den offenen Kommentar dazu. Gruppiere nach der Abteilung der Befragten.
Was die KI tut: lädt alle Cases, filtert im Speicher nach dem Bewertungswert, gruppiert nach Abteilung und liefert Ihnen genau die unzufriedenen Antworten mit ihren Kommentaren — Ihre Aufgabenliste in einem einzigen Prompt.
Antworten filtern und erkunden
Verwendete Tools: get_survey_cases_by_dates, get_survey_devices, get_survey_sources, get_survey_qualified, get_survey_disqualified
Beispiel-Prompts:
Wie viele Personen haben meine NPS-Umfrage im letzten Monat auf Mobile vs. Desktop geöffnet?
Meine Bürgerbefragung lief 3 Wochen. Zeig mir das Antwortvolumen pro Tag. Gab es einen Peak direkt nach dem Versand der Erinnerungs-E-Mail?
Von den 800 Personen, die die Umfrage gestartet haben — wie viele wurden vom Screener disqualifiziert? Wie verteilen sich die Disqualifikationsgründe?
Jede dieser Anfragen wäre sonst ein Klick-Marathon durchs QUESTIONSTAR-Dashboard plus Export. Über den MCP ist es ein Satz und eine 2-Sekunden-Antwort.
Befragte und Antworten programmgesteuert anlegen
Verwendete Tools: create_respondent, get_respondent, create_result_case, update_result_case
Diese Tools schreiben in QUESTIONSTAR hinein, nicht nur heraus. Reale Situationen, in denen das nützlich ist:
- Übertragung einer Papier-Umfrage. Sie haben bei einer Veranstaltung eine Papier-Umfrage durchgeführt. Geben Sie der KI die Fotos oder die abgetippte Tabelle — sie legt jeden Befragten und dessen Antworten als Case über
create_result_casean. - Übergabe vom CRM in die Umfrage. Ihr CRM enthält die Kontaktliste für die nächste Welle. Bitten Sie die KI, diese Kontakte als Befragte hinzuzufügen — ohne manuellen CSV-Upload.
- Eine Antwort korrigieren. Ein Teilnehmer mailt Ihnen, dass er seine Antwort präzisieren möchte. Die KI findet den Case über
get_respondentund aktualisiert ihn überupdate_result_case.
Beispiel-Prompt:
Hier sind 12 Papier-Antworten, die ich gerade abgetippt habe (CSV im Chat eingefügt). Füge sie zur Umfrage Mitarbeiterbefragung-Q4-Papier hinzu. Nimm die Namen aus Spalte A als Identifier.
Was die KI tut: parst Ihre Eingabe, ruft create_respondent pro Name auf, dann create_result_case mit den geparsten Antworten pro Befragtem und meldet zurück, wie viele Einträge erfolgreich angelegt wurden.
KI-Schreiboperationen sind echte Änderungen. Wenn Sie die KI um Hinzufügen oder Aktualisieren bitten, passieren diese Änderungen sofort in Ihrem echten QUESTIONSTAR-Konto.
Gute KI-Clients (Claude Desktop, ChatGPT) fragen vor jedem Schreib-Aufruf nach Erlaubnis. Machen Sie es sich zur Gewohnheit, zu lesen, was die KI vorhat, bevor Sie Allow klicken — besonders bei Massenoperationen. Wenn etwas seltsam aussieht, stoppt Decline die Aktion.
Datenexporte
Verwendete Tools: get_respondents_pipeline_csv, get_respondents_pipeline_xlsx, get_respondents_pipeline_spss
Beispiel-Prompts:
Exportiere meine Umfrage Kundenzufriedenheit nach SPSS, mit Wertelabels für die Bewertungsskalen.
Gib mir eine CSV mit allen Antworten zur Mitarbeiterbefragung aus Oktober 2025 — nur die Bewertungsfragen, mit deutschen Fragelabels in der Kopfzeile.
Die KI ruft das passende Pipeline-Tool auf und liefert eine herunterladbare Datei. Bei SPSS-Exporten bleiben die Wertelabels erhalten, sodass die Datei direkt in SPSS verwendet werden kann — ohne Import-Assistent.
Drei Stufen der Analyse
Die Tour oben deckt die Mechanik ab — lesen, filtern, exportieren. Der wirklich kraftvolle Teil des MCP kommt danach: wenn Sie die KI nicht nur abrufen, sondern analysieren und interpretieren lassen. Es folgen drei Stufen — vom schnellen Alltagsnutzen bis zu Forschungsmethoden.
Stufe 1 — Schnelle Zusammenfassungen und Berichte — ohne statistische Vorkenntnisse
Diese Stufe ersetzt routinemäßige Berichtsarbeit, die heute Stunden frisst. Sie brauchen kein statistisches Wissen. Die KI übernimmt die Synthese, Sie übernehmen das Feinabstimmen.
Beispiel 1 — Executive Summary fürs Management:
Schreibe eine einseitige Executive Summary der Kundenzufriedenheits-Umfrage Q3 2025 für die Geschäftsführung. Hebe die wichtigsten Trends, 3 Stärken und 3 dringende Handlungsfelder hervor. Zitiere 2 wörtliche Kundenstimmen pro Handlungsfeld.
Was Sie zurückbekommen: einen ausformulierten 1-Seiten-Text mit konkreten Prozentwerten, drei hervorgehobenen Stärken, drei konkreten Handlungsfeldern und kurzen, repräsentativen Zitaten. Oft zu 80-90 % versandfertig — Sie feilen an der Formulierung und versenden den Text.
Beispiel 2 — Vergleich zwischen Perioden:
Vergleiche die NPS-Ergebnisse zwischen Q2 und Q3. Hat sich der Wert verschoben? In welchen Segmenten am stärksten? Zieh dazu Themen aus offenen Antworten in Q3, die die Veränderung erklären könnten.
Was Sie zurückbekommen: das Wert-Delta mit Konfidenzintervall, die Aufschlüsselung pro Segment und 2-3 Themen aus den offenen Antworten, die auf die Ursachen hindeuten. Oft nützlicher als das reine NPS-Dashboard — es sagt Ihnen das Warum, nicht nur das Was.
Beispiel 3 — Team-spezifische Auswertung:
In meiner Mitarbeiterbefragung gibt es ein Filterfeld „Abteilung“. Gib mir für jede Abteilung eine 3-Satz-Zusammenfassung: Top-2 Stärken, Top-2 Sorgen, ein wörtliches Zitat. Als Liste formatiert.
Was Sie zurückbekommen: eine Mini-Zusammenfassung pro Abteilung, fertig zum Einfügen in die 1:1-Gespräche mit den Abteilungsleitungen. Eine personalisierte Sicht, die früher pro Team einen manuellen Excel-Filter-Durchgang erforderte.
Stufe 2 — Interpretation und Mustererkennung
QUESTIONSTAR liefert Kreuztabellen, t-Tests und Korrelationskoeffizienten von Haus aus — die meisten davon können Sie sich direkt im Bereich „Berichte“ anklicken. Was Standardberichte nicht tun:
- Ihnen erklären, was die Zahlen praktisch bedeuten,
- alle Fragekombinationen systematisch durchsuchen, um Erkenntnisse aufzuspüren, nach denen Sie nie gezielt gesucht hätten,
- offene Antworten in die Korrelationssuche einbeziehen,
- auf natürliche Respondenten-Segmente hinweisen, ohne dass Sie manuell filtern müssen.
Genau hier setzt der MCP an — als zusätzliche Schicht über der Analytik, die QS Ihnen schon liefert.
Beispiel 1 — Klarsprachliche Interpretation einer Kreuztabelle, die QS bereits berechnet hat:
Schau dir die Kreuztabelle Abteilung × Gesamtzufriedenheit aus meiner Mitarbeiterbefragung an. Was bedeuten die Zahlen praktisch? Welche Abteilung verdient sofortige Aufmerksamkeit, welche kann als Vorbild dienen, und wie wahrscheinlich ist es, dass die beobachteten Unterschiede zufällig sind?
Was Sie zurückbekommen: einen Absatz in klarer Sprache darüber, welche Abteilungen wirklich relevant sind, welche eher Rauschen sein dürften und wie ein konkreter Aktionsplan aussehen könnte. Der χ²-Test steht bereits in Ihrem QS-Bericht — die KI übersetzt die Zahlen in eine Geschichte und eine Empfehlung. Dasselbe gilt für t-Tests und jede Kreuztabelle, die der Standardbericht zeigt: Sie liefern die Tabelle, die KI liefert die Interpretation.
Beispiel 2 — Automatische Korrelationssuche über alle Fragen, inklusive offener Antworten:
Geh durch alle Paare von Fragen in der Kundenzufriedenheits-Umfrage und finde die 5 stärksten Zusammenhänge — auch unerwartete Paare. Bezieh die offenen Antworten ein: Wer in welcher Frage was schreibt, hängt das mit Antworten in anderen Fragen zusammen?
Was Sie zurückbekommen: eine sortierte Liste von Fragepaaren mit Korrelationskoeffizienten und — das ist der Teil, den die native Korrelationsfunktion in QS nicht kann — Querverbindungen, an denen offene Antworten beteiligt sind. So etwas wie: „Befragte, die in ihrem offenen Kommentar das Wort ‚zu teuer‘ verwenden, bewerten die Fragen zur technischen Qualität im Schnitt um 1,2 Punkte höher als der Sample-Durchschnitt. Die Preisbeschwerde hat also nichts mit Qualitätsbedenken zu tun.“
In QS könnten Sie jedes Paar geschlossener Fragen einzeln korrelieren — bei 30 Fragen sind das 435 Paare zum Durchklicken. Die KI erledigt das in einem Durchgang, hebt nur die aussagekräftigsten Funde hervor — und bezieht die offenen Antworten mit ein, was ein klassisches Korrelations-Tool nicht kann.
Beispiel 3 — Mittelwertvergleich von Gruppen (ANOVA — nicht im QS-Standardbericht enthalten):
In meiner Umfrage gibt es ein Filterfeld „Standort“. Vergleiche den durchschnittlichen Zufriedenheitswert pro Standort. Ist der Unterschied statistisch bedeutsam? Welche Standorte liegen deutlich über und welche unter dem Gesamtmittelwert?
Was Sie zurückbekommen: Mittelwerte und Standardabweichungen pro Standort, eine einfaktorielle ANOVA mit F-Statistik und p-Wert sowie Post-hoc-Paarvergleiche (Tukey HSD), damit Sie wissen, welche Standort-Paare sich tatsächlich unterscheiden. ANOVA gehört nicht zu den anklickbaren Tests im QS-Standardbericht — über den MCP haben Sie sie zur Hand.
Beispiel 4 — Segmente erkennen:
Schau dir die Antwortmuster aller Befragten an. Gibt es 2-3 natürliche Gruppen? Beschreibe jede Gruppe in einem Satz: wer sie sind und worin sie sich von den anderen unterscheiden.
Was Sie zurückbekommen: 2-3 Befragten-Profile in klarer Sprache — etwa „Gruppe A (35 %): durchgehend hohe Zufriedenheit über alle Fragen hinweg, langjährige Kunden aus größeren Unternehmen. Gruppe B (28 %): mittlere Werte mit wiederkehrenden Beschwerden über das Onboarding-Tempo. Gruppe C (37 %): gemischtes Muster, kein klares Profil.“
In QS müssten Sie manuell Filterkombinationen anlegen, zwischen Sub-Berichten hin- und herspringen und nach Augenmaß suchen, wo die Unterschiede liegen. Die KI macht das systematisch und zeigt Ihnen direkt auf die Segmente, die sie gefunden hat. Eine automatische Segmentierung ist nicht im Standard-Werkzeugkasten von QS — und selbst wenn Sie Ihre Segmente schon kennen, ist eine Ein-Satz-Beschreibung pro Segment qualitative Zusammenfassungsarbeit, die früher ein Marktforschungs-Berater übernommen hat.
Stufe 3 — Forschungsgerechte Analyse
Diese Stufe richtet sich an alle, die echte Forschung betreiben — Promotionen, Marktforschungs-Beratung — oder sich Methoden wünschen, die der Standardbericht von QUESTIONSTAR nicht abdeckt.
Beispiel 1 — Hauptkomponentenanalyse (PCA):
Führe eine PCA über die 12 Likert-Items im Block „Führungsbewertung“ durch. Wie viele Komponenten haben Eigenwert > 1? Zeig mir die Ladungsmatrix nach Varimax-Rotation. Schlag interpretierbare Namen für die latenten Konstrukte vor.
Was Sie zurückbekommen: die Scree-Plot-Daten, Eigenwerte, die rotierte Ladungsmatrix und die KI-Interpretation, welche Items zusammen z. B. „Klarheit der Kommunikation“, „fachliche Kompetenz“, „Empathie“ bilden. Nützlich für die Validierung von Skalen und für die Reduktion von 12 Fragen auf 3 inhaltlich tragfähige Indizes.
Beispiel 2 — K-Means-Clustering / Segmentierung:
Cluster meine Kundenbefragten anhand ihrer Antwortmuster zu den 6 Zufriedenheitsfragen. Probier k=2, 3, 4, 5. Welches k scheint am sinnvollsten? Beschreib für das gewählte k jeden Cluster in klarer Sprache.
Was Sie zurückbekommen: die Within-Cluster-Sum-of-Squares pro k (Daten für den Elbow-Plot), eine Empfehlung für ein k, die Cluster-Zentroide und einen Absatz pro Cluster — etwa „Cluster 2 (n=87): grundsätzlich zufrieden mit dem Produkt, aber durchgehend niedrige Werte bei der Reaktionszeit des Supports. Durchschnittliche Kundenbeziehungsdauer 4+ Jahre.“ Segmentierung, die früher einen Marktforschungs-Berater eine Woche kostete.
Beispiel 3 — Themen-Modellierung auf offenen Antworten:
Ich habe ca. 300 offene Antworten zur Frage „Was könnten wir besser machen?“. Identifiziere die 5 Hauptthemen. Pro Thema: ein Label, eine geschätzte Häufigkeit und 2-3 repräsentative Zitate.
Was Sie zurückbekommen: 5 Themen mit Häufigkeiten, etwa „Preissorgen (38 %, 114 Nennungen)“, „Lieferzeit (22 %, 66 Nennungen)“, plus die repräsentativsten Zitate pro Thema. Eine Codierung qualitativer Daten, die traditionell einen Hilfswissenschaftler einen ganzen Tag kostet.
Beispiel 4 — Stimmungsanalyse:
Klassifiziere für jeden offenen Kommentar in der Kundenzufriedenheits-Umfrage die Stimmung als positiv / neutral / negativ. Zeig mir die Gesamtverteilung — und aufgeschlüsselt nach dem Wert, den der Befragte in der geschlossenen Frage gegeben hat. Stimmen Stimmung im Kommentar und Zahlenwert überein?
Was Sie zurückbekommen: pro Kommentar ein Stimmungs-Label, die Gesamtverteilung, eine Kontingenz zwischen Stimmung und Bewertung sowie eine Beobachtung wie „15 % der Befragten, die den höchsten Zahlenwert gegeben haben, hinterließen dennoch einen als negativ klassifizierten Kommentar — diese lohnen einen manuellen Blick.“ Solche Diskrepanzen sind oft Gold wert.
Unerwartet nützlich
Ein paar Prompts, an die niemand zuerst denkt — die sich aber oft als die wertvollsten herausstellen. Das sind die „Moment, das geht?“-Momente: in keinem Analyse-Handbuch zu finden, aber im Nachhinein offensichtlich, sobald man sie einmal in Aktion gesehen hat.
Straight-Lining erkennen:
Finde Befragte, die ungewöhnlich schnell geantwortet haben oder die in einer Likert-Reihe durchgehend dieselbe Antwort gegeben haben. Möglicherweise Straight-Lining — sollten wir sie aus der Analyse ausschließen?
Eine schnelle Datenqualitäts-Prüfung, die Sie auf den meisten Plattformen selbst skripten müssten. Die KI markiert verdächtige Cases und gibt Ihnen die IDs zur Sichtung.
Widerspruchsdetektor:
Finde Antworten, bei denen der offene Kommentar dem Zahlenwert widerspricht — z. B. 5 Sterne mit einem beschwerdevollen Kommentar oder 1 Stern mit einem positiven Kommentar. Das sind meist die aufschlussreichsten Cases.
Ein Liebling der CX-Teams. In genau diesen Diskrepanzen steckt oft die eigentliche Erkenntnis — entweder wurde die Frage anders verstanden, oder die Bewertungsskala wird anders genutzt als die Designer angenommen haben.
Vokabular-Check:
Geh die offenen Antworten der letzten 6 Monate durch. Verwenden die Leute unsere neuen Produktnamen oder reden sie noch von den alten? Zitiere jeweils 5 Beispiele.
Brand- und Produktteams lieben das — es sagt Ihnen, ob Ihre Umbenennung tatsächlich bei den Kunden angekommen ist.
Vorschläge für die Fragebogengestaltung der nächsten Welle:
Schau dir die offenen Antworten an. Welche wiederkehrenden Themen werden genannt, für die ich keine geschlossene Frage habe? Schlag mir 3 neue geschlossene Fragen vor, die ich in der nächsten Welle aufnehmen sollte, um diese Themen quantitativ zu erfassen.
Die KI wird im Grunde zum gratis Fragebogen-Design-Berater. Besonders wertvoll bei laufenden Tracker-Studien.
Abbruch-Diagnose:
Meine Umfrage hat eine 60 %-Abschlussquote. Bei welcher Frage steigen die meisten aus? Was unterscheidet die Aussteigenden von den Beendern?
Kombiniert Case-für-Case-Fortschrittsdaten mit Befragten-Profilinformationen. Bringt Design-Probleme ans Licht (Frage zu lang, sensible Frage ohne vorangehende Vertrauensseite, technischer Fehler auf einer bestimmten Seite), für die Sie sonst ein UX-Audit bräuchten.
Übersetzungs-Plausibilitätscheck:
Meine Umfrage läuft auf Deutsch und Englisch. Vergleiche den durchschnittlichen Zufriedenheitswert zwischen den beiden Sprachversionen. Gibt es einen relevanten Unterschied? Falls ja, schau dir die Formulierung von Frage 3 in beiden Sprachen an — könnte die deutsche Version etwas anderes implizieren?
Ein häufiger stiller Fehler in mehrsprachigen Studien: ein feiner Formulierungsunterschied in einer Sprache verschiebt die Werte um einen halben Punkt. Die KI kann das erkennen; ein Dashboard nicht.
Wo die KI hilft — und wo Sie verifizieren sollten. Die KI über den MCP ist hervorragend für narrative Synthese, Mustererkennung, Segmentierung und explorative Analysen.
Für Statistiken, die in Publikationen landen sollen — p-Werte in einer Dissertation, Effektstärken für ein peer-reviewed Paper oder alles, wo eine nachvollziehbare Methodik zählt — behandeln Sie die KI-Ergebnisse als illustrativ. Verifizieren Sie mit SPSS, R, JASP oder einem vergleichbar auditierten Tool. Der MCP liefert die Rohdaten zuverlässig; die Schlussfolgerungen der KI sind exzellent, aber kein Ersatz für eine deterministische statistische Pipeline, wenn der Einsatz hoch ist.
Praktischer Tipp: bitten Sie die KI, ihre Methode Schritt für Schritt zu beschreiben. Eine gute KI sagt Ihnen genau, welchen Test sie verwendet hat, welche Voraussetzungen sie geprüft hat und welche sie übersprungen hat. So wird ihre Arbeit nachvollziehbar — und Sie wissen, ob Sie dem Ergebnis trauen können.
MCP mit n8n kombinieren — für automatisierte Berichte
Der MCP ist ein Request-Response-Werkzeug: Sie fragen, die KI antwortet, das Gespräch endet. Für ereignisgesteuerte Automatisierung — „immer wenn X passiert, mach Y automatisch“ — kombinieren Sie den MCP mit n8n.
Konkretes Rezept — wöchentlicher NPS-Digest in Slack:
Legen Sie in n8n einen Schedule-Trigger für jeden Montag um 9 Uhr an.
Fügen Sie einen HTTP-Request-Knoten hinzu, der Claude (oder OpenAI) mit einem Prompt wie diesem aufruft: „Fasse die NPS-Antworten der letzten Woche aus der QUESTIONSTAR-Umfrage Code XYZ zusammen. Top 3 Themen aus negativen Kommentaren. Format als Slack-Markdown.“
Die KI ruft die MCP-Tools auf, holt die Daten und erstellt die Zusammenfassung.
Fügen Sie einen Slack-Knoten hinzu, der die Zusammenfassung in Ihren Team-Kanal postet.
Jeden Montagmorgen bekommt Ihr Team einen frischen Digest, von der KI erstellt — ohne dass jemand ein Dashboard anfasst. Andere Rezepte folgen demselben Muster: neue hochpriorisierte Antwort → sofortiger Alert; monatlicher Kohortenvergleich → in eine Notion-Seite; Quartals-Review → in einen E-Mail-Entwurf.
Datenschutz, Sicherheit und DSGVO
Die Verbindung Ihrer Umfragedaten mit einem KI-Client ist eine ernsthafte Entscheidung, kein nebensächlicher Schritt. Was dabei tatsächlich passiert — und worauf Sie achten sollten.
Wie die Daten fließen
- Der MCP-Server schiebt von sich aus keine Daten irgendwohin. Er liegt inaktiv, bis ein KI-Client einen Tool-Aufruf macht. Aufrufe passieren nur, wenn Sie die KI bitten, etwas zu tun, das sie benötigt.
- Daten verlassen QUESTIONSTAR nur als Teil eines konkreten Tool-Aufrufs. Wenn Sie eine Executive Summary anfragen, holt die KI die dafür nötigen Antworten — nicht Ihren gesamten Account.
- Der KI-Client (Claude, ChatGPT, …) verarbeitet diese Daten auf seiner eigenen Infrastruktur für die Dauer Ihres Prompts. Was nach dem Chat passiert, hängt von der Datenspeicher-Richtlinie des Clients ab — siehe „KI-Client sorgfältig wählen“ weiter unten.
Token-Reichweite
- Ein API-Token erbt die Berechtigungen Ihres Accounts — und nichts darüber hinaus. Was Sie in Ihrem Account nicht sehen können, kann auch der Token nicht sehen.
- Der Token kann keine Rechte ausweiten — er kann nicht auf andere Accounts zugreifen, keine Abrechnung ändern, keine Berechtigungen verändern.
- Ein Token pro KI-Client ist die sicherste Variante — wenn ein Client sich fehlverhält oder kompromittiert wird, widerrufen Sie nur diesen einen.
- Rotieren Sie Tokens regelmäßig. Auf derselben Seite wie beim Erstellen: widerrufen (Mülleimer-Symbol), neuen erstellen, in den KI-Client einfügen.
KI-Client sorgfältig wählen
Sie vertrauen dem KI-Client alle Daten an, die der MCP zurückgibt. Anthropic (Claude), OpenAI (ChatGPT) und andere seriöse Anbieter haben öffentliche Datenschutzrichtlinien und bieten Enterprise-Modi mit strengeren Speicherregeln an. Bevor Sie sensible Daten anbinden, lesen Sie die relevante Richtlinie:
- Anthropic (Claude): Standardmäßig werden Konversationsdaten nicht zum Training verwendet. Enterprise-Pläne bieten zusätzlich Optionen zum Daten-Speicherort.
- OpenAI (ChatGPT): Verhalten unterscheidet sich zwischen Consumer- und Team-/Enterprise-Tarifen. Enterprise hat die strengsten No-Training-Defaults.
- Cursor, Zed usw.: Diese leiten meist über die APIs von Anthropic oder OpenAI weiter — es gilt jeweils die Richtlinie des darunterliegenden Anbieters.
DSGVO-Überlegungen
QUESTIONSTAR bleibt Ihr Auftragsverarbeiter; daran ändert der MCP rechtlich nichts. Der KI-Client ist ein eigenständiger Verarbeiter — prüfen Sie dessen Auftragsverarbeitungsvertrag (AVV) separat, sofern Ihre Daten personenbezogene Informationen im Sinne der DSGVO enthalten. Bei besonders sensiblen Projekten (medizinisch, behördlich, Minderjährige) nutzen Sie einen Enterprise-Tarif Ihres KI-Anbieters und dokumentieren Sie die Verarbeitungskette in Ihrer Verfahrensdokumentation.
Fehlerbehebung
Verbindung schlägt fehl oder „MCP-Server nicht erreichbar“
- Prüfen Sie die exakte URL:
https://mcp.questionstar.de/mcpoderhttps://mcp.questionstar.com/mcp. Das abschließende/mcpist erforderlich. - Prüfen Sie den Bearer-Präfix im Authorization-Header:
Bearer IHR_TOKEN— ein Leerzeichen zwischen Bearer und Token, keine Anführungszeichen. - Starten Sie Claude Desktop nach dem Hinzufügen des Connectors neu. Manche Versionen laden MCP-Server nur beim Start.
„Tool-Aufruf nicht autorisiert“ oder keine Reaktion
- Ihr KI-Client fragt standardmäßig pro Tool-Aufruf um Erlaubnis. Wenn der Prompt zu hängen scheint, suchen Sie in der Client-Oberfläche nach einem Berechtigungsdialog und klicken Sie auf Allow.
- Falls Sie ein Tool zuvor abgelehnt haben und es jetzt wieder zulassen möchten: in Claude Desktop die Connector-Einstellungen öffnen und das betroffene Tool wieder aktivieren.
Die KI liefert eine leere Antwort oder falsche Daten
- Manchmal ruft die KI ein Tool mit dem falschen Parameter auf (z. B. falscher Umfrage-Code). Bitten Sie sie, zuerst die verfügbaren Umfragen aufzulisten und die richtige zu bestätigen — und stellen Sie dann die ursprüngliche Frage erneut.
- Für komplexe Prompts (Analyse auf Stufe 2 / Stufe 3) bitten Sie die KI, ihren Rechenweg zu zeigen: „Erklär mir deine Berechnung Schritt für Schritt, bevor du das Endergebnis lieferst.“ So werden Fehler sichtbar, und oft korrigiert sich die KI selbst.
„Meine Zahlen stimmen nicht mit dem QUESTIONSTAR-Dashboard überein“
- Datumsbereiche. Stellen Sie sicher, dass KI und Dashboard auf denselben Zeitraum gefiltert sind — die KI nimmt eventuell standardmäßig „alle Zeit“, während das Dashboard „letzte 30 Tage“ zeigt.
- Disqualifizierte Antworten. Das Dashboard schließt disqualifizierte Cases manchmal automatisch aus; die KI bezieht sie unter Umständen mit ein, sofern Sie nichts anderes sagen. Bitten Sie: „Berechne neu — ohne disqualifizierte Antworten.“
- Offene vs. abgeschlossene Antworten. Manche Dashboard-Kacheln zählen nur vollständig abgeschlossene Einreichungen;
get_result_casesliefert standardmäßig alle. Seien Sie im Prompt explizit, was Sie wollen.
Verwandte Integrationen
- n8n — für ereignisgesteuerte Workflows (neue Antwort kommt rein → KI-Prompt ausführen → irgendwohin posten).
- Zapier — No-Code-Weiterleitung von QUESTIONSTAR-Ereignissen an tausende Apps.
- REST API — direkter programmatischer Zugriff, ohne KI-Schicht.
- Google Looker Studio & Microsoft Power BI — für vordefinierte Dashboards, die sich automatisch aktualisieren.
Der MCP glänzt bei flexibler, narrativer Ad-hoc-Arbeit; die anderen glänzen bei strukturierter, wiederholbarer, dashboard-basierter Arbeit. Die meisten Teams nutzen am Ende beides.