Marktforschung, Umfragemethodik und ihre praktische Anwendung — vom Forschungsproblem zum Ergebnisbericht.
Dr. Paul Marx · QUESTIONSTAR
Folie 01 · 261
QUESTIONSTAR
Erstellen · Befragen · Auswerten · Berichten
1
Kapitel 1 · Einführungskurs
Grundlagen der Umfrageforschung
Marktforschung, Umfragemethodik und ihre praktische Anwendung — vom Forschungsproblem zum Ergebnisbericht.
Dr. Paul Marx · QUESTIONSTAR
Folie 01 · 261
QUESTIONSTAR
Erstellen · Befragen · Auswerten · Berichten
Kapitel 1 · Einführungskurs
Grundlagen der Umfrageforschung
Marktforschung, Umfragemethodik und ihre praktische Anwendung — vom Forschungsproblem zum Ergebnisbericht.
Dr. Paul Marx · QUESTIONSTAR
Folie 01 · 261
QUESTIONSTAR
Erstellen · Befragen · Auswerten · Berichten
Kapitel 1 · Einführungskurs
Grundlagen der Umfrageforschung
Methodisch fundiert. Praktisch anwendbar.
Marktforschung, Umfragemethodik und ihre praktische Anwendung — vom Forschungsproblem zum Ergebnisbericht.
Dr. Paul Marx · QUESTIONSTAR
Kapitel 1 · EinführungInhaltsverzeichnis
Inhalt
01Einführung
1.1Marktforschung und Umfrage
1.2Typologie der Marktforschung
02Umfrage: Messung und Skalierung
2.1Einführung
2.2Komparative Skalen
2.3Nicht-komparative Skalen
2.4Latente Konstrukte
2.5Reliabilität und Validität
03Fragebogen
3.1Fragen stellen
3.2Bewältigung der mangelnden Antwortfähigkeit
3.3Bewältigung der mangelnden Antwortbereitschaft
3.4Erhöhung der Antwortbereitschaft
3.5Reihenfolge von Fragen
3.6Wie geht es weiter?
04Stichproben
4.1Nicht-zufällige Stichproben
4.2Zufällige Stichproben
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.4Größe der Stichprobe
05Datenanalyse: Übersicht über statistische Techniken
5.1Deskriptive Statistik:Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik:Kann man die Ergebnisse auf die Grundgesamtheit übertragen?
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
06Fortgeschrittene Techniken der Marktforschung: Einige nützliche Konzepte
6.1Conjoint-Analyse
6.2Marktsimulationen
6.3Segmentierung
6.4Wahrnehmungskarten
07Ergebnisse Berichten
QUESTIONSTAR · Dr. Paul Marx02 / 274
Kapitel 1Sektionsübersicht
1
Kapitel
Einführung
1.1Marktforschung und Umfrage
1.2Typologie der Marktforschung
QUESTIONSTAR · Dr. Paul Marx03 / 274
Kapitel 1 · EinführungSektionsübersicht
1
Kapitel
Einführung
1.1Marktforschung und Umfrage
1.2Typologie der Marktforschung
QUESTIONSTAR · Dr. Paul Marx04 / 274
1.1 · Marktforschung und UmfrageDefinitionen
Was ist Forschung?
Forschung ist
Alle systematischen Bestrebungen und Bemühungen, um neue Erkenntnisse für Wissenschaft oder Industrie zu erlangen.
— Lexikon
Forschung ist
Suche und Sammlung von Informationen und Ideen in Antwort auf eine spezifische Fragestellung.
— Praktische Definition
QUESTIONSTAR · Dr. Paul Marx05 / 274
1.1 · Marktforschung und UmfrageDefinition
Umfrage
Umfrage
Umfrage ist eine der populärsten Methoden, primäre Daten zu erheben, wobei der Forscher mit Befragten interagiert, um Informationen über Einstellungen, Meinungen, Wissen und Verhaltensweisen von Menschen zu gewinnen.
1Einstellungen & Meinungen — wie Menschen denken und urteilen
2Wissen — was Menschen kennen und verstehen
3Verhaltensweisen — was Menschen tatsächlich tun
QUESTIONSTAR · Dr. Paul Marx06 / 274
1.1 · Marktforschung und UmfrageProblemverständnis
Marktforschung
EntscheidungsträgerEntscheidungsproblemForscherUnzufriedene KundenGesunkener MarktanteilFallende VerkäufeGeringer TrafficÜber WasserSichtbare und messbare SymptomeGrenzwertige Leistung vom VerkaufsteamMangelhafte BelieferungUnzureichende Qualität der ProdukteUnethischer Umgang mit KundenSchlechtes ImageUnter WasserDas eigentliche Business- bzw. Entscheidungsproblem
QUESTIONSTAR · Dr. Paul Marx07 / 274
1.1 · Marktforschung und UmfrageAnwendungsbereiche
Praktische Nutzung von Umfragen
Disziplin
Anwendung
Soziologie und Politikwissenschaften
Meinungsforschung, Identifikation der Einstellungen von Bevölkerungsgruppen gegenüber sozial bedeutenden Phänomenen, Ereignissen und Fakten; Wahlforschung (z. B. Sonntagsfrage), …
Markt- und Verbraucherforschung, Messung von Imagewahrnehmung, Präferenzen, Zufriedenheit und Loyalität (NPS), Zahlungsbereitschaft; Segmentierung, Positionierung, Preisbestimmung, Werbetests, Usability von Webseiten, …
Wissenschaft (im Allgemeinen)
Untersuchung von Beziehungen zwischen zwei oder mehreren Variablen, Faktoren, Phänomenen; Skalen- und Methodenentwicklung für wissenschaftliche und praktische Zwecke, …
Bildung
Wissenstests (Multiple-Choice-Prüfungen), Studenten- und Lehrerevaluation; großangelegte Bildungsstudien (z. B. PISA), …
…
… und viele weitere Anwendungsfelder
QUESTIONSTAR · Dr. Paul Marx08 / 274
1.1 · Marktforschung und UmfrageProzessmodell
Prozess der Marktforschung — die „5 D’s"
D1Definitionsphase
Informationsbedarf identifizieren
Forschungsproblem und -fragen definieren
Forschungsziele festlegen
Informationswert prüfen
D2Designphase
Budget
Datenquellen
Forschungsmethoden
Stichprobenplan
Kontaktmethoden
Methoden der Datenanalyse
D3Datenerhebungsphase
Daten entsprechend dem Plan erheben
oder externen Dienstleister beauftragen
D4Datenanalysephase
Daten statistisch und subjektiv analysieren
Antworten und Implikationen ableiten
D5Dateninterpretationsphase
Ergebnisse der Datenanalyse formulieren
Forschungsbericht aufbereiten
Ergebnisse haben keinen praktischen Wert, wenn das Forschungsproblem nur vage definiert ist.
Der Plan muss im Voraus festgelegt, dennoch flexibel sein — um notwendige Anpassungen einbauen zu können.
Diese Phase ist sehr kostspielig und sehr fehleranfällig.
Wahl der Datenanalysemethode hängt im Wesentlichen vom Forschungstyp ab.
1.1 · Marktforschung und UmfrageGrenzen der Marktforschung
Wann sollte man keine Marktforschungsprojekte starten?
Fall
Kommentar
Vage Ziele
Wenn Manager sich nicht darauf einigen können, welche Informationen sie zur Entscheidungsfindung brauchen. Marktforschung hilft nur, wenn sie eine konkrete Frage untersucht.
Fixierte Haltung
Wenn die Entscheidung bereits getroffen ist und die Studie nur als „Abstempelung" eines vorgefassten Plans dienen soll.
Zu spät
Wenn Ergebnisse zu spät bereitgestellt werden, um die Entscheidung noch beeinflussen zu können.
Schlechtes Timing
Wenn ein Produkt in der Degenerationsphase ist, macht es wenig Sinn, neue Produktvariationen zu erforschen.
Unzureichende Ressourcen
Es lohnt sich nicht, eine quantitative Studie aufzusetzen, solange keine statistisch signifikante Stichprobe realisierbar ist — oder wenn die Finanzen nicht reichen, die resultierenden Entscheidungen umzusetzen.
Kosten überwiegen Vorteile
Der erwartete Informationswert sollte die Kosten der Datenerhebung und -analyse übersteigen.
Ergebnisse nicht aktionsfähig
Wenn z. B. psychographische Charakteristiken genutzt werden, die nicht helfen, konkrete Entscheidungen zu treffen.
Informationen nicht erforderlich
Wenn entscheidungsrelevante Informationen bereits vorhanden sind.
QUESTIONSTAR · Dr. Paul Marx10 / 274
Kapitel 1 · EinführungSektionsübersicht
1
Kapitel
Einführung
1.1Marktforschung und Umfrage
1.2Typologie der Marktforschung
QUESTIONSTAR · Dr. Paul Marx11 / 274
1.2 · Typologie der MarktforschungDrei Ordnungskriterien
Typologie der Marktforschung
Kriterium 1
Nach Zielen
Explorativauch diagnostisch
Deskriptiv
Kausalauch prädiktiv, experimentell
Kriterium 2
Nach Datenquellen
Primärselbst erhobene Daten
Sekundärbereits vorhandene Daten
Kriterium 3
Nach Methodologie
Qualitativverstehen
Quantitativmessen
QUESTIONSTAR · Dr. Paul Marx12 / 274
1.2 · Typologie der MarktforschungNach Forschungszielen
Marktforschungstypologie nach Zielen
Unsicherheit beeinflusst den Marktforschungstyp
Unsicher
Sicher
Niedrige Klarheit
Explorativ
auch diagnostisch
Problem noch ungenau definiert; Hypothesen werden gebildet.
Analyse von Daten und Aktionen, um Probleme besser zu verstehen
Welche Gründe könnten hinter der sinkenden Kundenzufriedenheit stecken?
Was hält Erstkäufer davon ab, erneut zu kaufen?
Mittlere Klarheit
Deskriptiv
Phänomene werden systematisch beschrieben und gemessen.
Sammeln und Präsentation von Fakten: wer, was, wann, wo, wie?
Wie sieht der historische Umsatztrend in der Branche aus?
Wie sind die Einstellungen der Konsumenten gegenüber unserem Produkt?
Hohe Klarheit
Kausal
auch prädiktiv, experimentell
Ursache-Wirkungs-Beziehungen werden geprüft.
Analyse der Ursache-Wirkungs-Beziehungen — „Was wäre wenn?“
Vorhersage der Ergebnisse von Marketing-Aktionen
Einfluss von Werbeausgaben auf den Umsatz (wieviel bringt ein Werbe-Euro?)
Kleinere Umfragen, Focus-Groups, Interviews
Größere Umfragen, Beobachtung, usw.
Experimente, A/B-Tests, Konsumentenpanels
QUESTIONSTAR · Dr. Paul Marx13 / 274
1.2 · Typologie der MarktforschungNach Datenquellen
Marktforschungstypologie nach Datenquellen
DatenquellePrimär
Generierung von Daten, die bisher noch nicht vorliegen. Diese Daten werden analysiert und können ggf. vom Forscher veröffentlicht werden.
Ermöglicht die Berechnung des prozentualen Anteils der Probanden, die ein Objekt bevorzugen
Rangordnung kann geschätzt werden (unter Annahme der Transitivität)
Mögliche Erweiterungen: Alternative „keine Unterschiede", abgestufter Vergleich
−
Nachteile
Anzahl der Vergleiche wächst schneller als die Anzahl der Objekte — für n Objekte n(n−1)/2 Vergleiche
Reihenfolgeeffekte möglich (Einfluss der Präsentationsreihenfolge)
Aus Präferenz von A über B folgt nicht, dass der Proband A mag
Wenig realistisch für reale Wahlsituationen mit mehreren Alternativen
Verletzung der Transitivitätsannahme möglich
QUESTIONSTAR · Dr. Paul Marx31 / 274
2.2 · Komparative SkalenOrdinale Daten
Verletzung der Transitivitätsannahme in paarweisen Vergleichen
Derselbe Proband, dieselbe Paarung — und trotzdem widersprüchliche Antworten:
Vergleich 1Apfel>Tomate
Vergleich 2Tomate>Apfel
Aus „Apfel ≻ Tomate" und „Tomate ≻ Apfel" lässt sich keine Rangordnung bilden — die Präferenzen sind widersprüchlich (intransitiv).
QUESTIONSTAR · Dr. Paul Marx32 / 274
2.2 · Komparative SkalenOrdinale Daten
Verletzung der Transitivität bei Aggregation von Präferenzen
Proband #1
1Apfel
2Tomate
3Orange
Proband #2
1Tomate
2Orange
3Apfel
Proband #3
1Orange
2Apfel
3Tomate
Stimmenzählung
Apfel ≻ Tomate2 : 1
Tomate ≻ Orange2 : 1
Orange ≻ Apfel2 : 1
Apfel ≻ Tomate ≻ Orange ≻ Apfel. Apfel wird gleichzeitig am meisten und am wenigsten präferiert — die Gruppenpräferenzen sind inkonsistent!
QUESTIONSTAR · Dr. Paul Marx33 / 274
2.2 · Komparative SkalenMethode
Komparative Skalen: Rangordnungsverfahren
i
Rangordnungsverfahren
Probanden bringen mehrere Objekte in eine Reihenfolge — basierend auf einem bestimmten Kriterium.
Ordnen Sie bitte die unten aufgeführten Marken von Erfrischungsgetränken entsprechend Ihrer Präferenzen an. Dafür wählen Sie zunächst die Marke aus, die Sie am meisten präferieren, und weisen Sie ihr den Rangplatz 1 zu. Anschließend weisen Sie den Rangplatz 2 der zweitbesten Marke. Setzen Sie die Bewertung fort, bis Sie allen Marken einen Rangplatz zugewiesen haben. Die letzte, am wenigsten präferierte Marke muss den Rangplatz 5 bekommen.
Keine zwei Marken dürfen denselben Rangplatz erhalten.
Das Kriterium der Präferenz ist ganz Ihnen überlassen. Es gibt keine richtige oder falsche Antworten. Versuchen Sie einfach, konsistent zu sein.
Marke
Rangplatz
Pepsi-Cola
_________
Coca-Cola
_________
Red Bull
_________
Sprite
_________
7-Up
_________
QUESTIONSTAR · Dr. Paul Marx34 / 274
2.2 · Komparative SkalenPraxisbeispiel
Rangordnungsverfahren: Beispiel
Was würdest du dir zum Geburtstag wünschen?
Ziehe jeden Gegenstand in den passenden Bereich — Rangplatz 1 = am meisten gewünscht.
Top-3 Wunschliste
1
Smartwatch
2
Spielkonsole
3
Smartphone
Würde ich mir nicht wünschen
Kabellose Kopfhörer
QUESTIONSTAR · Dr. Paul Marx35 / 274
2.2 · Komparative SkalenPraxisbeispiel
Rangordnungsverfahren: Beispiele
Drag & DropTop-3 auswählen & ordnen
„Was ist Ihnen beim Einkauf am wichtigsten? Ordnen Sie die 3 wichtigsten Gründe."
Zur Auswahl
Öffnungszeiten
Kundenservice
Rückgaberecht
Ihre Rangordnung
1
Auswahl
2
Online-Angebot
3
Preis
Rang-MatrixRang je Zeile anklicken
„Bringen Sie die Themenbereiche in Ihre Reihenfolge (1–6)."
123456
Kommunikation & Medien2
Digitale Medientechnik6
Internet3
Büro-Peripherie4
IT-Sicherheit5
Software & Systemintegration1
QUESTIONSTAR · Dr. Paul Marx36 / 274
2.2 · Komparative SkalenPraxisbeispiel
Rangordnungsverfahren: Beispiel
Welche Frucht mögen Sie am liebsten? — Ziehen Sie die Früchte auf die Skala.
Drag & Drop
Orange
Kiwi
Apfel
Banane
Erdbeere
Überhaupt nicht gernSehr gern
QUESTIONSTAR · Dr. Paul Marx37 / 274
2.2 · Komparative SkalenBewertung
Rangordnungsverfahren: Vor- und Nachteile
+
Vorteile
Direkter Vergleich
Realitätsnäher als paarweise Vergleiche
Anzahl der Vergleiche ist nur (n − 1)
Einfacher zu verstehen
Nehmen weniger Zeit in Anspruch
Keine nicht-transitiven Antworten
Daten können in paarweise Vergleiche konvertiert werden
Gut für Messung von Marken- und Eigenschaftspräferenzen
−
Nachteile
Aus Präferenz von A über B folgt nicht, dass der Proband A mag
Kein Nullpunkt — keine Trennung zwischen Mögen und Nicht-Mögen
Lediglich ordinale Daten
Verletzung der Transitivitätsannahme möglich (bei Aggregation)
QUESTIONSTAR · Dr. Paul Marx38 / 274
2.2 · Komparative SkalenMethode
Komparative Skalen: Konstantsummenverfahren
i
Konstantsummenverfahren
Probanden verteilen einen fixierten Betrag (z. B. Punkte, Euros, Chips, %) vollständig über ein Set von Objekten — nach einem bestimmten Kriterium.
Unterstehend ist eine Liste von fünf Eigenschaften von Autos aufgeführt. Bitte verteilen Sie 100 Punkte über diese Eigenschaften so, dass die Anzahl der Punkte, die Sie einer Eigenschaft zuweisen, deren relative Wichtigkeit für Sie widerspiegelt. Je mehr Punkte eine Eigenschaft bekommt, desto wichtiger ist sie für Sie. Wenn eine Eigenschaft für Sie unwichtig ist, weisen Sie ihr 0 Punkte zu. Wenn eine Eigenschaft doppelt so wichtig ist wie eine andere, weisen Sie ihr doppelt so viele Punkte zu.
Eigenschaft
Punkte
Geschwindigkeit
0
Komfort
15
Getriebetyp (manuell/Automatik)
5
Kraftstoff (Benzin/Diesel)
35
Preis
45
Summe
100
QUESTIONSTAR · Dr. Paul Marx39 / 274
2.2 · Komparative SkalenDurchschnittliche Bewertung in drei Segmenten
Konstantsummenverfahren: Beispiel der Auswertung
Attribut
Segment 1
Segment 2
Segment 3
Geschwindigkeit
0
17
53
Komfort
15
23
30
Getriebe (manuell/Automatik)
5
21
10
Kraftstoff (Benzin/Diesel)
35
12
7
Preis
45
27
0
Summe
100
100
100
QUESTIONSTAR · Dr. Paul Marx40 / 274
2.2 · Komparative SkalenPraxisbeispiel
Konstantsummenverfahren: Beispiel
Welche Merkmale eines Mietwagens sind Ihnen am wichtigsten? Verteilen Sie 100 € darauf.
Summe: 100 / 100 €✓
0 €
übrig
Zurücksetzen
Vollkasko
25 €
Klimaanlage
20 €
Navigation (GPS)
15 €
Auto max. 3 Jahre alt
10 €
Teilkasko
10 €
Kraftstoffwahl (Benzin/Diesel)
5 €
CD-Player
5 €
Radio
5 €
Schiebedach
5 €
Umgebungskarte
0 €
Rückgabe-Hinweise
0 €
QUESTIONSTAR · Dr. Paul Marx41 / 274
2.2 · Komparative SkalenPraxisbeispiel
Konstantsummenverfahren: Beispiele
SliderAuf Skala ziehen
„Welcher Anteil Ihrer Einkäufe entfällt auf …?"
Kosmetik
25 %
Damenmode
20 %
Herrenmode
15 %
Schuhe
25 %
Sonstiges
15 %
Gesamt100 / 100 %
EingabefeldWerte eintippen
„Wie verteilen Sie 100 % Ihres Monatsbudgets?"
Wohnen40
Essen25
Freizeit20
Sonstiges15
Verbleibend0
Klick-BalkenBalken anklicken
„Wie verteilt sich Ihre Internetnutzung?"
privat
63 %
beruflich
37 %
Gesamt100 %
QUESTIONSTAR · Dr. Paul Marx42 / 274
2.2 · Komparative SkalenBewertung
Konstantsummenverfahren: Vor- und Nachteile
+
Vorteile
Kann kleine Unterschiede zwischen den Objekten messen, ohne zu viel Zeit zu beanspruchen
Metrisch skaliert → flexible Auswahl an Analyseverfahren
−
Nachteile
Ergebnisse sind auf die Liste der beurteilten Objekte beschränkt — keine Aussagen über Objekte außerhalb der Liste
Relativ hohe kognitive Belastung der Probanden, insb. bei langen Listen
Anfällig für Rechenfehler (z. B. Verteilung von 108 oder 94 Punkten)
QUESTIONSTAR · Dr. Paul Marx43 / 274
2.2 · Komparative SkalenMethode
Komparative Skalen: Q-Sortierung
i
Q-Sortierung
Rangordnungsverfahren, bei dem Objekte (in Hinblick auf ein bestimmtes Merkmal) in Stapeln sortiert werden. Genutzt, um eine hohe Anzahl an Objekten (60–140) schnell untereinander zu vergleichen.
Die Anzahl der Objekte je Stapel ist so begrenzt, dass alle Stapel zusammen die Form einer Normalverteilung nachbilden.
Das Gesundheitsministerium hat 25 Maßnahmen zur Umsetzung in Krankenhäusern entwickelt. Ordnen Sie diese nach ihrer Wirksamkeit gegen die Infektionsausbreitung ein — bitte nur eine Maßnahme pro Box.
1
2
3
4
5
4
3
2
1
Äußerst wirksamGanz und gar nicht wirksam
QUESTIONSTAR · Dr. Paul Marx44 / 274
Kapitel 1 · Teil 2Sektionsübersicht
2
Teil
Umfrage: Messung und Skalierung
2.1Einführung
2.2Komparative Skalen
2.3Nicht-komparative Skalen
2.4Latente Konstrukte
2.5Reliabilität und Validität
QUESTIONSTAR · Dr. Paul Marx45 / 274
2.3 · Nicht-komparative SkalenFokus
Typologie von Skalierungsverfahren
Wurzel
Skalierung
Komparative Skalen
Objekte werden direkt miteinander verglichen
Paarweise VergleicheRangordnungsverfahrenKonstantsummenverfahrenQ-Sortierung & andere
Probanden bewerten Objekte, indem sie eine entsprechende Position auf einer Linie markieren, die von einem Extrem zum anderen eines bestimmten Kriteriums läuft.
Jeder Teilnehmer dreht während der Reizdarbietung — z. B. einem TV-Werbespot — ein Drehrad. So entsteht eine kontinuierliche Bewertung in Echtzeit, Sekunde für Sekunde — aggregiert über alle Teilnehmer und getrennt nach Segmenten.
Drehrad-Handgerät
Aggregierte Echtzeit-Kurven über die Spot-Dauer — getrennt nach Segmenten (0 = „Not Appealing“ … 100 = „Very Appealing“).Teilnehmer bewerten live während der Vorführung.
Probanden geben an, inwieweit sie den aufgeführten Aussagen zustimmen — anhand einer 5- oder 7-Punkte-Skala, die von einem Extrem zum anderen reicht.
Im Folgenden sind unterschiedliche Aussagen über „Real" aufgelistet. Bitte geben Sie an, wie stark Sie diesen Aussagen zustimmen:
Stimme gar nicht zu
Stimme nicht zu
Neutral
Stimme zu
Stimme voll und ganz zu
Real verkauft hochwertige Waren
Real hat schlechten Service umgekehrt
Einkaufen bei Real macht mir Spaß
Real bietet eine Mischung aus verschiedenen Marken
Die Kreditpolitik in Real ist schrecklich umgekehrt
Ich mag die Werbung von Real nicht umgekehrt
Die Preise bei Real sind fair
Wichtig: Die Aussagen 2, 5 und 6 sind umgekehrt formuliert. Vor der Datenanalyse müssen diese Skalen umgekodiert werden — eine höhere Zahl soll stets eine bessere Einstellung bedeuten.
QUESTIONSTAR · Dr. Paul Marx49 / 274
2.3 · Nicht-komparative SkalenLikert-Skala · in Online-Umfragen
Likert-Skala: Beispiele
Format · Radio-Buttons
Wie zufrieden sind Sie insgesamt mit unserem Kundenservice?
Sehr unzufrieden
Unzufrieden
Weder noch
Zufrieden
Sehr zufrieden
Format · Segmentierte Buttons
„Der Bestellvorgang war einfach." — Wie sehr stimmen Sie zu?
Trifft überhaupt nicht zu
Trifft eher nicht zu
Teils teils
Trifft eher zu
Trifft voll und ganz zu
Format · Nummerierte Skala
Wie wichtig ist Ihnen ein kostenloser Rückversand?
Zweipolige Rating-Skala, deren Extreme mit jeweils gegensätzlichen Adjektiven beschrieben werden. Erlaubt die Messung mehrdimensionaler Einstellungen und deren Profildarstellung.
Wie schätzen Sie das Erscheinungsbild von „Kaufhof" ein? Bitte kreuzen Sie an, inwieweit Sie jeweils mehr zu der einen oder anderen Ausprägung tendieren.
Kaufhof ist …
Stark
Schwach
Unzuverlässig
Zuverlässig
Modern
Altmodisch
Kalt
Warm
Sorgfältig
Leichtsinnig
Hinweis: Die negativen Adjektive erscheinen mal links, mal rechts. So lässt sich nachträglich kontrollieren, ob Probanden gedankenlos immer dieselbe Seite ankreuzen, ohne die Adjektive zu lesen.
Misst Selbsteinschätzung sowie Einstellungen gegenüber Personen oder Produkten. Jeder Punkt entspricht dem Mittelwert oder Median der jeweiligen Skala — die Verbindung der Punkte ergibt das Profil.
Hoch
Stark
Zuverlässig
Kalt
Modern
Gut
Freundlich
Hässlich
Aktiv
Jung
Vorsichtig
Klein
Sanft
Robust
Bescheiden
Tief
Schwach
Unzuverlässig
Heiß
Langsam
Schlecht
Feindlich
Schön
Passiv
Alt
Sorglos
Groß
Abstoßend
Empfindlich
Angeberisch
Beispielhaftes Profil eines Objekts — sieben Stufen zwischen den gegensätzlichen Polen.
Eine unipolare Ratingskala mit 10 Kategorien von −5 bis +5, ohne Neutralpunkt (0).
Sie wird oft als Alternative zum semantischen Differential verwendet, wenn sich kein sinnvolles Paar gegensätzlicher Adjektive finden lässt.
Plus-Zahl = die Phrase trifft zu, Minus-Zahl = sie trifft nicht zu. Je größer der Betrag, desto stärker.
Wie zutreffend beschreiben die folgenden Phrasen das Geschäft „Real"? Wählen Sie pro Phrase eine Zahl zwischen +5 (trifft voll zu) und −5 (trifft gar nicht zu).
+5+4+3+2+1
Hohe Qualität
-1-2-3-4-5
+5+4+3+2+1
Schlechter Service
-1-2-3-4-5
QUESTIONSTAR · Dr. Paul Marx55 / 274
2.3 · Nicht-komparative SkalenÜberblick
Wichtigste nicht-komparative Skalen
Skala
Beschreibung
Beispiele
Vorteile
Nachteile
Kontinuierliche Ratingskalen
Markierung auf einer kontinuierlichen Linie
Reaktion auf TV-Werbespots
Einfach zu bilden
Manuelle (nicht PC-gestützte) Auswertung kann sehr mühsam sein
Likert-Skaladiskret
Grad der Zustimmung auf einer Skala von 1 (stimme ganz und gar nicht zu) bis 5 (stimme vollkommen zu)
Messung von Einstellungen
Einfach zu verstehen, zu verwenden und zu bilden
Zeitaufwendiger
Semantisches Differentialdiskret
Zweipolige, siebenstufige Ratingskala mit entgegengesetzten Adjektiven an den Polen
Marken-, Produkt- und Firmenimage
Vielseitig
Keine Aussage darüber, ob die Daten intervallskaliert sind
Stapel-Skaladiskret
Unipolare Zehn-Punkte-Skala von −5 bis +5 ohne Neutralpunkt (0)
Messung von Einstellungen und Image
Einfach zu konstruieren und in Telefon-Umfragen einzusetzen
Es gibt keine einzig optimale Anzahl — traditionell werden Skalen mit fünf bis neun Kategorien verwendet.
2
Balanciert vs. nicht-balanciert
Generell sollte die Skala balanciert sein, um objektive Ergebnisse erzielen zu können.
3
Gerade vs. ungerade Anzahl
Wenn eine neutrale bzw. indifferente Antwort für manche Probanden in Frage kommt, sollte man eine ungerade Anzahl von Kategorien wählen.
4
Obligatorische vs. nicht-obligatorische Antwort
Können einige Probanden keine Meinung haben, verbessern nicht-obligatorische Fragen die Genauigkeit der Ergebnisse.
5
Beschriftung der Skalenpunkte
Nicht jeder Punkt muss beschriftet werden — entscheidend ist, Ambivalenz zu vermeiden und beide Pole (bei ungerader Anzahl auch die Mitte) eindeutig zu benennen.
QUESTIONSTAR · Dr. Paul Marx57 / 274
2.3 · Konstruktion von RatingskalenGestaltungsfrage 1
Anzahl von Antwortkategorien
1
Anzahl von Antwortkategorien
Es gibt keine einzig optimale Anzahl — traditionell werden Skalen mit fünf bis neun Antwortkategorien verwendet.
Mehr Kategorien erfassen feinere Unterschiede — aber die meisten Probanden kommen nur mit wenigen Kategorien zurecht.
Involvement & Wissen
mehrwenn Probanden an der Bewertung interessiert sind oder über tiefes Wissen zum Objekt verfügen.
Natur der Objekte
mehrwenn feine Unterschiede für die Objekte charakteristisch sind.
Modus der Datenerhebung
wenigerbei Telefoninterviews, wo Skalen schwerer zu überblicken sind.
2.3 · Konstruktion von RatingskalenGestaltungsfrage 2
Balancierte oder nicht-balancierte Skalen
2
Balanciert vs. nicht-balanciert
Generell sollte die Skala balanciert sein, um objektive Ergebnisse erzielen zu können.
Balancierte Skala
Sehr gut
Gut
Weder gut noch schlecht
Schlecht
Sehr schlecht
2 positiv · 1 neutral · 2 negativ — symmetrisch.
Nicht-balancierte Skala
Extrem gut
Sehr gut
Gut
Angemessen
Schlecht
Sehr schlecht
4 positiv · 2 negativ — verzerrt zu positiven Urteilen.
QUESTIONSTAR · Dr. Paul Marx59 / 274
2.3 · Konstruktion von RatingskalenGestaltungsfrage 3
Gerade oder ungerade Anzahl von Antwortkategorien
3
Gerade vs. ungerade Anzahl
Wenn eine neutrale bzw. indifferente Antwort für manche Probanden in Frage kommt, sollte man eine ungerade Anzahl von Kategorien wählen.
Ungerade Anzahl — mit Mitte
Stimme gar nicht zu
Stimme nicht zu
Neutral
Stimme zu
Stimme voll zu
Erlaubt eine neutrale Antwort
Gerade Anzahl — ohne Mitte
Stimme gar nicht zu
Stimme nicht zu
Stimme zu
Stimme voll zu
Erzwingt eine Tendenz
Die mittlere Option zieht viele Unsichere an — und solche, die ihre Meinung nur ungern offenbaren.
Das kann die Maße der zentralen Tendenz und der Varianz verzerren.
Wollen bzw. brauchen wir „Kontrast" bei kontroversen Einstellungen?
QUESTIONSTAR · Dr. Paul Marx60 / 274
2.3 · Konstruktion von RatingskalenGestaltungsfrage 4
Obligatorische oder nicht-obligatorische Antwort?
4
Obligatorische vs. nicht-obligatorische Antwort
Wenn einige Probanden keine Meinung haben können, verbessern nicht-obligatorische Fragen die Genauigkeit der Ergebnisse.
Wollen die Probanden nicht antworten — oder haben sie schlicht keine Meinung?
„Weiß nicht" / „Nicht zutreffend"
✓Bei sachlichen Fragen und Wissensabfragen einsetzen.
✕Nicht bei der Messung von Einstellungen und Meinungen.
Filterführung
Gezielt steuern, dass Probanden nur Fragen erhalten, die sie auch beantworten können — statt Antworten zu erzwingen.
Faustregel: Fragen ohne „weiß nicht" liefern tendenziell mehr genaue Daten — aber nur, wenn die Probanden tatsächlich eine Meinung haben.
QUESTIONSTAR · Dr. Paul Marx61 / 274
2.3 · Konstruktion von RatingskalenGestaltungsfrage 5
Beschriftung der Skalenpunkte
5
Beschriftung der Skalenpunkte
Nicht jeder Punkt muss beschriftet werden — entscheidend ist, Ambivalenz zu vermeiden und beide Pole (bei ungerader Anzahl auch die Mitte) eindeutig zu benennen.
Soll jeder Skalenpunkt beschriftet werden — oder reichen einige ausgewählte Punkte?
Alle oder nur einige?
Keine eindeutige Evidenz, dass die Beschriftung aller Punkte besser ist als nur ausgewählter — die Forschung zeigt keinen wesentlichen Unterschied.
Zu viel verwirrt
Zu viele, zu fein differenzierte Labels können Befragte verwirren, wenn sich Begriffe kaum abgrenzen lassen (z. B. „eher positiv" vs. „ziemlich positiv").
Entscheidend: Eindeutigkeit
Ambivalenz vermeiden. Beide Pole klar benennen, bei ungerader Anzahl auch die Mitte — es muss klar sein, welches Kontinuum die Skala abbildet.
Wenig Platz
Reduzierte Beschriftung besonders sinnvoll bei Schiebereglern oder Matrix-Fragen, wo volle Beschriftung schnell unübersichtlich wird.
QUESTIONSTAR · Dr. Paul Marx62 / 274
2.3 · Konstruktion von RatingskalenBeschriftung der Skalenpunkte · Varianten
Wie viel beschriften? — Vier Varianten
Dieselbe Frage: „Wie wahrscheinlich kaufen Sie Produkt A erneut?"
Alle Punkte beschriftet
maximale Führung
Sehr unwahrscheinlich
Eher unwahrscheinlich
Weder noch
Eher wahrscheinlich
Sehr wahrscheinlich
Nur Zahlen
minimale Beschriftung
1
2
3
4
5
Nur Pole beschriftet
Endpunkte benannt
Sehr unwahrscheinlich
Sehr wahrscheinlich
Pole + Zahlen
Endpunkte benannt, Stufen nummeriert
1Sehr unwahrscheinlich
2
3
4
5Sehr wahrscheinlich
QUESTIONSTAR · Dr. Paul Marx63 / 274
2.3 · Konstruktion von RatingskalenFormulierung der Skalenpole
Spitze vs. flache Antwortverteilung
Wie extrem die Endpunkte sprachlich formuliert sind, prägt die Form der Antwortverteilung.
Extreme Pole → spitze Verteilung
äußerst zufriedenüberhaupt nicht zufrieden
Befragte meiden die Extreme — die Antworten bündeln sich in der Mitte.
Moderate Pole → flache Verteilung
zufriedenunzufrieden
Befragte nutzen auch die Endpunkte — die Antworten verteilen sich differenzierter.
Der Secure Customer Index fasst drei Loyalitäts-Indikatoren zu einer Kennzahl zusammen. Als Secure Customer gilt nur, wer auf allen drei Dimensionen die Top-Stufe (5) wählt — die Schnittmenge. Die Segmente geben jeweils den Anteil (%) der Kunden an.
Zufriedenheit im Allgemeinen
5 — sehr zufrieden
4 — eher zufrieden
3 — weder zufrieden noch unzufrieden
2 — eher unzufrieden
1 — sehr unzufrieden
Bereitschaft zur Weiterempfehlung
5 — werde ganz sicher weiterempfehlen
4 — werde wahrscheinlich weiterempfehlen
3 — unentschieden
2 — werde wahrscheinlich nicht weiterempfehlen
1 — werde ganz sicher nicht weiterempfehlen
Wahrscheinlichkeit der Wiederverwendung
5 — werde ganz sicher weiterverwenden
4 — werde wahrscheinlich wiederverwenden
3 — unentschieden
2 — werde wahrscheinlich nicht wiederverwenden
1 — werde ganz sicher nicht wiederverwenden
Secure Customers
Anteil, der sehr zufrieden ist / ganz sicher wiederverwenden / ganz sicher weiterempfehlen wird.
Günstige Einstellung
Anteil mit mind. der zweitbesten Stufe auf allen drei Dimensionen der Zufriedenheit und Loyalität.
Verletzte Konsumenten
Anteil: eher zufrieden · unentschieden · unentschieden.
Gefährdete Konsumenten
Anteil: eher/nicht zufrieden · wahrscheinlich oder sicher nicht wiederverwenden/weiterempfehlen.
Sehr zufriedenWerde definitiv wieder nutzenWerde definitiv weiterempfehlenSecure Customer
Quelle: D. Randall Brandt (1996), „Secure Customer Index", Maritz Research
QUESTIONSTAR · Dr. Paul Marx70 / 274
2.4 · Latente KonstrukteAnwendung · Loyalität über zwei Perioden
Erweiterter Secure Customer Index von Burke Inc.
Burke erweitert den Secure Customer Index um zwei zusätzliche Loyalitäts-Dimensionen (insgesamt fünf) und verknüpft den in Periode 1 gemessenen Loyalitätsindex mit dem tatsächlichen Share of Wallet in Periode 2 — also dem Anteil der Ausgaben, den der Kunde der Marke widmet.
Periode 1
Loyalitätsindex
→
Periode 2
Share of Wallet (0 % – 100 %)
Fünf Dimensionen — jeweils erhoben über folgende Frage
Zufriedenheit im Allgemeinen„Wie zufrieden sind Sie mit (MARKE/UNT.) im Allgemeinen?"
Bereitschaft zur Weiterempfehlung„Wenn man Sie bitten würde, ein Unternehmen aus (BRANCHE) zu empfehlen, wie wahrscheinlich ist es, dass Sie (MARKE/UNT.) empfehlen werden?"
Wahrscheinlichkeit des Wiederverkaufs„Wie wahrscheinlich ist es, dass Sie (MARKE/UNT.) weiterverwenden werden?"
Verdiente Loyalität„(MARKE/UNT.) hat meine Loyalität verdient."
Bevorzugtes Unternehmen„Ich ziehe (MARKE/UNT.) allen anderen Anbietern vor."
Quelle: Burke Inc. · http://www.burke.com/
QUESTIONSTAR · Dr. Paul Marx71 / 274
Kapitel 1 · Teil 2Sektionsübersicht
2
Teil
Umfrage: Messung und Skalierung
2.1Einführung
2.2Komparative Skalen
2.3Nicht-komparative Skalen
2.4Latente Konstrukte
2.5Reliabilität und Validität
QUESTIONSTAR · Dr. Paul Marx72 / 274
2.5 · Reliabilität und ValiditätGrundmodell der Messung
Das True-Score-Modell
Das Ergebnis der Messung ist nicht der wahre Wert einer Charakteristik, sondern nur eine Beobachtung davon.
XObeobachtet=XTwahr+XSsystemat.+XRzufällig
XObeobachteter Wert einer Charakteristik
XTder wahre Wert der Charakteristik
XSsystematischer Fehler
XRZufallsfehler
QUESTIONSTAR · Dr. Paul Marx73 / 274
2.5 · Reliabilität und ValiditätZwei Gütekriterien der Messung
Reliabilität und Validität
Reliabilität
Zuverlässigkeit
Gibt an, wie zuverlässig ein Messinstrument misst — d. h. wie konsistent die Ergebnisse bei wiederholten Messungen sind.
Kein Zufallsfehler: XR⟶ 0 ⟹ XO⟶ XT + XS
Maßzahl ist Cronbachs Alpha (0 ≤ α ≤ 1)
Werte von α ≥ 0,7 gelten als akzeptabel
XO = XT + XS + XR
Validität
Gültigkeit
Gibt an, inwieweit ein Messinstrument auch tatsächlich den Sachverhalt misst, den es messen soll.
Also: inwiefern gemessene Unterschiede tatsächlichen Unterschieden zwischen den Objekten entsprechen (Güte der Messung).
✗Aus Reliabilität folgt nicht Validität.XR = 0, XS ≠ 0 ⟹ XO = XT + XS ≠ XT
Reliabilität ist eine notwendige, aber nicht hinreichende Bedingung der Validität.
QUESTIONSTAR · Dr. Paul Marx75 / 274
2.5 · Reliabilität und ValiditätWarum beides zählt
„
Der Zweck einer Skala ist es, uns zu ermöglichen, die Probanden mit der höchsten Genauigkeit und Reliabilität abzubilden. Wir können nicht das Eine ohne das Andere haben und dabei unseren Daten vertrauen.
Bart GambleVice President Client Services Burke, Inc. (2000–2003)
QUESTIONSTAR · Dr. Paul Marx76 / 274
2.5 · Reliabilität und ValiditätAnwendung · Eine einzige Frage
Net Promoter Score® — Prädiktor des Unternehmenswachstums?
„Wie wahrscheinlich ist es, dass Sie Unternehmen/Marke/Produkt X einem Freund, Verwandten oder Kollegen weiterempfehlen werden?"
0
1
2
3
4
5
6
7
8
9
10
Kritiker
Passive
Promotoren
Net Promoter Score=% Promotoren−% Kritiker→NPS−100 % … +100 %
5–10 %
Durchschnittliche Unternehmen
45 %
Unternehmen mit offenem Wachstumspotential
50–80 %
Marktführer mit hohem Wachstumspotential
Quelle: Reichheld, Fred (2003) „One Number You Need to Grow", Harvard Business Review
QUESTIONSTAR · Dr. Paul Marx77 / 274
2.5 · Reliabilität und ValiditätNet Promoter Score · Warnung
Net Promoter Score®: Warnung
„
Obwohl die „Weiterempfehlungs-Frage“ bei weitem die beste Einzelfrage für die Vorhersage von Konsumentenverhalten für eine Reihe von Branchen ist — sie ist nicht die beste Frage für alle Branchen. Deshalb müssen Unternehmen ihre Hausaufgaben machen und die Verbindung zwischen der Antwort und dem darauffolgenden Konsumentenverhalten für ihr Geschäftsfeld empirisch überprüfen.
Fred Reichheld, 2011Quelle: Reichheld, F. & Markey, R. (2011). The Ultimate Question 2.0. Harvard Business Review Press, S. 50–51.
QUESTIONSTAR · Dr. Paul Marx78 / 274
Kapitel 3Sektionsübersicht
3
Kapitel
Fragebogen
3.1Fragen stellen
3.2Bewältigung der mangelnden Antwortfähigkeit
3.3Bewältigung der mangelnden Antwortbereitschaft
3.4Erhöhung der Antwortbereitschaft
3.5Reihenfolge von Fragen
3.6Wie geht es weiter?
QUESTIONSTAR · Dr. Paul Marx79 / 274
Kapitel 3 · FragebogenDefinition & Ziele
Fragebogen
Fragebogen
Ein Fragebogen ist eine formalisierte Liste von Fragen, die dazu dient, Informationen von Befragten zu erheben.
1Informationsbedarf in ein Set eindeutiger Fragen „übersetzen", die Probanden beantworten können und wollen
2Probanden motivieren, an der Umfrage teilzunehmen und sie abzuschließen
3Antwortfehler minimieren
QUESTIONSTAR · Dr. Paul Marx80 / 274
3.1 · Fragen stellenZwei Gegensatzpaare
Fragetechniken und Befragungstaktik
FormGeschlossene vs. Offene Fragen
Geschlossen: Auswahl aus vorgegebenen Antwortalternativen. + einfach zu analysieren, kein kognitiver Stress − automatische, nicht durchdachte Antworten
Offen: Antwortalternativen nicht vorgegeben. + unbegrenzte Möglichkeiten, beansprucht das Gedächtnis − komplexe Codierung, Verweigerung möglich
Analysegeschlossen → leicht auswertbar · offen → reichhaltig, aber aufwendig
AnsatzDirekte vs. Indirekte Fragen
Direkt: die Frage zielt unmittelbar auf den interessierenden Sachverhalt.
Indirekt: der Sachverhalt wird über eine Umweg-Formulierung erschlossen — schont sensible oder schwer artikulierbare Themen.
Beispieledirekt: „Trinken Sie täglich Alkohol?" indirekt: „Welche Getränke bevorzugen Sie zu Mahlzeiten?"
QUESTIONSTAR · Dr. Paul Marx81 / 274
3.1 · Fragen stellenEin klassisches Experiment
Einfluss der Formulierung auf die Antwort
Frage A
„Darf man beim Beten rauchen?"
→ Antwort: Nein
Frage B
„Darf man beim Rauchen beten?"
→ Antwort: Ja
Gleiche Handlung, andere Formulierung — gegensätzliche Antworten. Quelle: Noelle-Neumann & Petersen (1998), S. 192 · n = 2100, p < 0,05
Anteil der Antworten (%)
Ja
57
51
Nein
25
30
Unsicher
18
19
„Glauben Sie überhaupt an die große Liebe?"
„Glauben Sie an die große Liebe?"
n = 2100, p < 0,05
QUESTIONSTAR · Dr. Paul Marx82 / 274
3.1 · Fragen stellenLeitfragen
Was soll man bei der Entwicklung eines Fragebogens berücksichtigen?
Mehrdeutigkeit, Verwirrung und Unklarheit vermeiden
i
Die sechs W's
Formulieren Sie die Frage in Bezug auf wer, was, wann, wo, warum und wie. Besonders wichtig: wer, was, wann, wo.
✕Beispiel
„Welche Marke von Shampoo nutzen Sie?"
✓Fragen Sie stattdessen
„Welche Marke oder Marken von Shampoo haben Sie persönlich zu Hause während des letzten Monats genutzt? Falls Sie mehr als eine genutzt haben, nennen Sie bitte alle."
QUESTIONSTAR · Dr. Paul Marx86 / 274
3.1 · Fragen stellenRegel 1 · Analyse
„Welche Marke von Shampoo nutzen Sie?" — was ist unklar?
W
Aspekt
Warum unklar?
Wer
Bezugsperson
Nicht klar, ob nur der Proband selbst oder sein gesamter Haushalt gemeint ist.
Was
Bezugsobjekt
Nicht klar, wie zu antworten ist, falls mehrere Marken genutzt werden.
Wann
Bezugszeitraum
Kein Bezugszeitraum angegeben — heute Morgen, diese Woche oder das ganze Jahr?
Wo
Situation / Ort
Zu Hause, im Fitness-Studio, im Urlaub, auf Geschäftsreise?
Für Eindeutigkeit statt Mehrdeutigkeit: alle realistischen Situationen mitdenken und passende Antwortalternativen vorbereiten — inkl. „trifft nicht zu" und Filterführung.
✕Beispiel
„Welchen Computertyp besitzen Sie?"
WindowsMac OS
✓Besser
„Welche Computer besitzen Sie?"
keinenWindowsMac OSAnderes
✕Beispiel
„Sind Sie zufrieden mit Ihrer jetzigen Kfz-Versicherung?"
JaNein
✓Noch besser · Filterführung
1. „Haben Sie eine Kfz-Versicherung?" (wenn nein → Frage 3) 2. „Sind Sie zufrieden mit Ihrer jetzigen Kfz-Versicherung?"
QUESTIONSTAR · Dr. Paul Marx88 / 274
3.1 · Fragen stellenRegel 1 · Eindeutige Skalen
Skalen und Antwortalternativen müssen eindeutig sein
i
Vage Häufigkeiten
Wörter wie „selten", „manchmal" oder „oft" bedeuten für jeden Probanden etwas anderes. Nutzen Sie konkrete, abgegrenzte Häufigkeitsangaben.
✕Beispiel
„Wie oft kaufen Sie in einem typischen Monat in einem Supermarkt ein?"
NiemalsSeltenManchmalOftRegulär
✓Fragen Sie stattdessen
„Wie oft kaufen Sie in einem typischen Monat in einem Supermarkt ein?"
weniger als 1 Mal1–2 Mal3–4 Malöfter als 4 Mal
QUESTIONSTAR · Dr. Paul Marx89 / 274
3.1 · Fragen stellenRegel 2 · Einfache Sprache
Fachsprache, Slang und Abkürzungen vermeiden
i
Einfache Wörter
Verwenden Sie einfache, alltägliche Wörter — keine Fachbegriffe, kein Jargon. Jeder Proband muss die Frage sofort verstehen.
✕Beispiel
„Glauben Sie, dass die Distribution der Erfrischungsgetränke adäquat ist?"
✓Fragen Sie stattdessen
„Sind Erfrischungsgetränke einfach zu finden, wann immer Sie sie kaufen möchten?"
✕Auch unklar
„Geben Sie Ihr bereinigtes Nettoeinkommen im vergangenen Jahr an."
QUESTIONSTAR · Dr. Paul Marx90 / 274
3.1 · Fragen stellenRegel 3 · Ein Aspekt pro Frage
Doppelläufige Fragen vermeiden
i
Ein Aspekt pro Frage
Jede Frage soll sich auf nur einen Aspekt konzentrieren. Sonst weiß man nicht, worauf sich die Antwort bezieht.
✕Beispiel
„Ist Ihrer Meinung nach Coca-Cola lecker und erfrischend?"
✓Fragen Sie stattdessen
1. „Ist Ihrer Meinung nach Coca-Cola lecker?" 2. „Ist Ihrer Meinung nach Coca-Cola erfrischend?"
QUESTIONSTAR · Dr. Paul Marx91 / 274
3.1 · Fragen stellenRegel 4 · Keine Suggestion
Führende Fragen vermeiden
i
Keine Suggestion
Wenn Sie eine bestimmte Antwort wollen, brauchen Sie die Frage nicht zu stellen. Führende Formulierungen lenken den Probanden.
✕Beispiel
„Helfen Sie der Umwelt, indem Sie Einkaufstaschen aus Stoff nutzen?"
Meinungen und Überzeugungen stellen die realen Fakten oft nur verzerrt dar. Fragen Sie nach beiden Fakten getrennt.
✕Beispiel
„Glauben Sie, dass höher gebildete Menschen tendenziell öfter Pelzkleidung tragen?"
✓Fragen Sie stattdessen
1. „Was ist Ihr Bildungsstand?" 2. „Tragen Sie Pelzkleidung?"
QUESTIONSTAR · Dr. Paul Marx95 / 274
3.1 · Fragen stellenRegel 8 · Konkret fragen
Verallgemeinerungen und Schätzungen vermeiden
i
Kein Kopfrechnen
Zwingen Sie den Probanden nicht, sein Gedächtnis und seine mathematischen Fähigkeiten anzustrengen. Fragen Sie die Bausteine ab.
✕Beispiel
„Wie hoch sind die jährlichen Pro-Kopf-Ausgaben für Lebensmittel in Ihrem Haushalt?"
✓Fragen Sie stattdessen
1. „Wie viel Geld wird in Ihrem Haushalt monatlich für Lebensmittel ausgegeben?" 2. „Wie viele Mitglieder hat Ihr Haushalt?"
QUESTIONSTAR · Dr. Paul Marx96 / 274
Kapitel 3Sektionsübersicht
3
Kapitel
Fragebogen
3.1Fragen stellen
3.2Bewältigung der mangelnden Antwortfähigkeit
3.3Bewältigung der mangelnden Antwortbereitschaft
3.4Erhöhung der Antwortbereitschaft
3.5Reihenfolge von Fragen
3.6Wie geht es weiter?
QUESTIONSTAR · Dr. Paul Marx97 / 274
3.2 · Mangelnde AntwortfähigkeitDrei Hürden
Bewältigung der mangelnden Antwortfähigkeit
1
Ist der Proband informiert?
Hat er die nötige Information überhaupt?
2
Kann der Proband sich erinnern?
Ist die Information abrufbar?
3
Kann der Proband artikulieren?
Kann er die Antwort formulieren?
QUESTIONSTAR · Dr. Paul Marx98 / 274
3.2 · Mangelnde AntwortfähigkeitHürde 1 · Information
Ist der Proband informiert?
Probanden beantworten Fragen oft, auch wenn sie nicht informiert sind.
Klassisches Experiment: Auf eine Frage zur fiktiven „Zentrale für Verbraucherbeschwerden" antworteten 51,9 % der Anwälte und 75 % der Bevölkerung — obwohl es eine solche Zentrale gar nicht gibt.
✓Gegenmittel 1 · Filter-Fragen
Vorab nach Kenntnis bzw. Einkaufshäufigkeit fragen — z. B. in einer Studie zu 10 Einkaufsläden.
✓Gegenmittel 2 · „Weiß nicht"
Eine „Weiß nicht"-Antwortalternative anbieten, statt Antworten zu erzwingen.
Manche Fragen erscheinen im falschen Kontext unangemessen. Führen Sie sie mit einem erklärenden Statement ein.
Fragen zu Hygienegewohnheiten wirken in einer medizinischen Umfrage normal — in einer Umfrage über Fast-Food-Restaurants dagegen unpassend.
✓Einleitendes Statement
„Als Fast-Food-Restaurant sind wir bemüht, unseren Kunden eine saubere und hygienische Umgebung zu bieten. Deshalb möchten wir Ihnen nun einige Fragen zu Ihren Hygienegewohnheiten stellen."
Erklären Sie, warum die Informationen benötigt werden — sonst wirken sie aufdringlich.
Warum interessiert sich ein Cerealien-Hersteller für Alter, Einkommen und Beruf der Probanden?
✓Informationsanfrage legitimieren
„Um zu verstehen, wie sich der Konsum von Frühstückscerealien zwischen Personen mit verschiedenem Alter, Einkommen und Beruf unterscheidet, benötigen wir von Ihnen noch folgende Informationen …"
QUESTIONSTAR · Dr. Paul Marx106 / 274
Kapitel 3Sektionsübersicht
3
Kapitel
Fragebogen
3.1Fragen stellen
3.2Bewältigung der mangelnden Antwortfähigkeit
3.3Bewältigung der mangelnden Antwortbereitschaft
3.4Erhöhung der Antwortbereitschaft
3.5Reihenfolge von Fragen
3.6Wie geht es weiter?
QUESTIONSTAR · Dr. Paul Marx107 / 274
3.4 · Erhöhung der AntwortbereitschaftUmgang mit sensiblen Themen
Sensible Themen behandeln
1
Sensible Themen ans Ende des Fragebogens stellen
2
Mit dem Statement einleiten, dass das Verhalten nur im Allgemeinen von Interesse ist
3
Fragen in der dritten Person formulieren (als ob sie andere Menschen betreffen)
4
Die Frage in einer Gruppe anderer Fragen verstecken
5
Antwortalternativen vorgeben, statt konkrete Angaben oder Zahlen abzufragen
Sollten interessant, einfach und nicht abschreckend sein — sie entscheiden über die weitere Teilnahme.
2
Informationstyp
Faustregel: zuerst die forschungsrelevanten, dann die Klassifikations- und zuletzt die Identifikationsinformationen abfragen.
3
Schwierige Fragen
Sensible, peinliche, komplizierte oder mühsame Fragen möglichst weit hinten platzieren.
QUESTIONSTAR · Dr. Paul Marx110 / 274
3.5 · Reihenfolge von FragenAusstrahlungseffekte
Trichterung und Verzweigungslogik
Trichterung (Funneling)
Allgemeines vor Konkretem
1Allgemein zuerst
„Welche Aspekte spielen für Sie bei der Auswahl eines Kaufhauses eine wichtige Rolle?"
2Dann konkret
„Wie wichtig ist Ihnen die Bequemlichkeit der Lage bei der Auswahl eines Kaufhauses?"
Verzweigungslogik
Logische Anordnung
Die Frage, zu der verzweigt wird, möglichst nah an der auslösenden Frage platzieren.
Verzweigungen so anordnen, dass Probanden nicht vorhersehen können, welche Zusatzinfos abgefragt werden.
QUESTIONSTAR · Dr. Paul Marx111 / 274
3.5 · Reihenfolge von FragenBeispiel · Verzweigungslogik
Beispiel: Ablaufplan einer Umfrage
QUESTIONSTAR · Dr. Paul Marx112 / 274
Kapitel 3Sektionsübersicht
3
Kapitel
Fragebogen
3.1Fragen stellen
3.2Bewältigung der mangelnden Antwortfähigkeit
3.3Bewältigung der mangelnden Antwortbereitschaft
3.4Erhöhung der Antwortbereitschaft
3.5Reihenfolge von Fragen
3.6Wie geht es weiter?
QUESTIONSTAR · Dr. Paul Marx113 / 274
3.6 · Wie geht es weiter?Die Einleitung
Eine überzeugende Einleitung gestalten
1
Interesse der Probanden wecken
2
Gründe und Ziele erklären
3
Probanden um Hilfe bitten
4
Betonen, dass ihre Unterstützung wertvoll ist
5
Sagen, wie lange die Umfrage dauert
6
Anonymität betonen
7
Anreize schaffen
Vorzugsweise nicht-monetäre Anreize.
QUESTIONSTAR · Dr. Paul Marx114 / 274
3.6 · Wie geht es weiter?Der wichtigste Schritt
Pretesten! Pretesten! Pretesten!
Testen Sie den Fragebogen vor dem Einsatz an einer kleinen Stichprobe — und prüfen Sie jeden Aspekt:
Inhalt der FragenWortlaut / FormulierungReihenfolgeForm & LayoutSchwierigkeit der FrageAnleitungenAnalyseverfahren
QUESTIONSTAR · Dr. Paul Marx115 / 274
Kapitel 3 · FragebogenZusammenfassung
Zusammenfassung
Ablaufplan
Entwickeln Sie einen Ablaufplan der erforderlichen Informationen — ausgehend vom (Markt-)Forschungsproblem.
Ist die Sequenz ausgelegt, werden die Zusammenhänge klar.
Stimmen Sie die erhobenen Daten auf den Informationsbedarf ab.
Legen Sie für jeden Bereich ein klares Ziel fest — daraus ergeben sich die Fragen.
„Kritikerhut" aufsetzen
Gehen Sie zurück zum Ablaufplan und fragen Sie zu jeder Information:
„Muss ich das wirklich wissen — und weiß ich, was ich damit tue?"
… statt „Wäre schön zu wissen, brauche ich aber nicht unbedingt."
QUESTIONSTAR · Dr. Paul Marx116 / 274
Kapitel 4Sektionsübersicht
4
Kapitel
Stichproben
4.1Nicht-zufällige Stichproben
4.2Zufällige Stichproben
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.4Größe der Stichprobe
QUESTIONSTAR · Dr. Paul Marx117 / 274
Kapitel 4 · StichprobenWarum Sampling zählt
Der berühmteste Schlagzeilenfehler der Welt
Dewey Defeats Truman
1948: Die Chicago Daily Tribune verkündet das falsche Wahlergebnis. Präsident Harry Truman schlägt Thomas Dewey — entgegen aller Umfragen. Grund: voreingenommene, ungenaue Meinungsumfrage.
QUESTIONSTAR · Dr. Paul Marx118 / 274
Kapitel 4 · StichprobenGrundbegriffe
Auswahl der Stichprobe (Sampling)
Grundgesamtheit (Population)
Personenkreis, den wir verstehen wollen — oft segmentiert nach demografischen/psychografischen Merkmalen.
Stichprobe (Sample)
repräsentative Teilmenge der Grundgesamtheit
Die meisten Umfragen können nicht jede Person befragen. Stattdessen wird eine Stichprobe gezogen und untersucht — diese Prozedur heißt Sampling.
Ist Sampling richtig gemacht, lassen sich die Umfrageergebnisse auf die ganze Grundgesamtheit übertragen.
Ist die Stichprobe fehlerhaft gezogen, sind alle Daten nutzlos.
QUESTIONSTAR · Dr. Paul Marx119 / 274
Kapitel 4 · StichprobenGrundbegriffe
Auswahl der Stichprobe (Sampling)
Grundgesamtheit (Population)
Personenkreis, den wir verstehen wollen — oft segmentiert nach demografischen/psychografischen Merkmalen.
Stichprobe (Sample)
repräsentative Teilmenge der Grundgesamtheit
Probanden
Menschen, die antworten
Aber nicht alle Ausgewählten antworten auch: Wer tatsächlich teilnimmt, sind die Probanden.
Die Probanden sind eine Teilmenge der Stichprobe — und nur sie liefern am Ende die Daten. Verzerrt sich diese Gruppe, verzerrt sich das Ergebnis.
QUESTIONSTAR · Dr. Paul Marx120 / 274
Kapitel 4 · StichprobenZwei grundlegende Methoden
Sampling: Zwei grundlegende Methoden
Methode 1
Nicht-zufällige Auswahl
Die Stichprobe wird nach dem persönlichen Urteil des Forschers gezogen — oft aufs Geratewohl (Convenience Sample, z. B. Passanten im Einkaufszentrum).
In der Regel kostengünstig; erlaubt eine grobe Einschätzung der Populationsparameter.
Aber: Der Stichprobenfehler ist nicht berechenbar → Ergebnisse sind nicht repräsentativ und nicht auf die Grundgesamtheit übertragbar.
Methode 2
Zufällige Auswahl
Die Stichprobe wird nach dem Zufallsprinzip ausgewählt.
Erlaubt statistische Verfahren zur Bestimmung der Genauigkeit der geschätzten Populationsparameter sowie zur Beurteilung ihrer Konfidenzintervalle.
Ergebnisse sind verallgemeinerbar und können auf die Grundgesamtheit übertragen werden.
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.4Größe der Stichprobe
QUESTIONSTAR · Dr. Paul Marx123 / 274
4.1 · Nicht-zufällige StichprobenVerfahren 1
Willkürliche Auswahl
Bei der willkürlichen Auswahl (Auswahl aufs Geratewohl) gelangen die Probanden unkontrolliert in die Stichprobe — meist aus Bequemlichkeit. Oft nur, weil sie zur richtigen Zeit am richtigen Ort sind.
Typische Beispiele
Studenten & Mitglieder öffentlicher OrganisationenUmfragen in Kaufläden ohne Qualifizierung der ProbandenUmfragen auf den StraßenAbriss-Fragebögen in Katalogen und Zeitschriften
QUESTIONSTAR · Dr. Paul Marx124 / 274
4.1 · Nicht-zufällige StichprobenVerfahren 2
Bewusste Auswahl
Die bewusste Auswahl ist eine Form der willkürlichen Auswahl, bei der Probanden nach dem Ermessen des Forschers in die Stichprobe gelangen.
Typische Beispiele
TestmärkteEinkaufsingenieure in der industriellen MarktforschungMütter als „Nutzer" von Windeln
QUESTIONSTAR · Dr. Paul Marx125 / 274
4.1 · Nicht-zufällige StichprobenVerfahren 3
Quotenplan
Die Stichprobe wird nach vorgegebenen Kontrollmerkmalen (z. B. Geschlecht, Alter, Einkommen) gezogen, sodass sie die Struktur der Grundgesamtheit proportional widerspiegelt. Die Objekte werden meist aufs Geratewohl ausgewählt — sie müssen jedoch den Quotenplan erfüllen.
Kontrollmerkmal
Grundgesamtheit
Stichprobe
Anteil %
Anteil %
Anzahl
Geschlecht — männlich
48
48
480
weiblich
52
52
520
Summe
100
100
1000
Alter — 18–30
27
27
270
31–45
39
39
390
45–60
16
16
160
über 60
18
18
180
Summe
100
100
1000
Wird oft in Online-Umfragen verwendet.
QUESTIONSTAR · Dr. Paul Marx126 / 274
4.1 · Nicht-zufällige StichprobenVerfahren 4
Schneeball-Verfahren auch Ketten-Verfahren
1Die erste Probandengruppe wird (in der Regel) zufällig ausgewählt.
2Nach dem Interview benennen sie weitere Personen der Zielgruppe.
3Nachfolgende Probanden werden über Weiterempfehlungen ausgewählt.
Gut zur Lokalisierung seltener Eigenschaften: schwer erreichbare Probanden (Staatsangestellte, Geschäftsführer, Obdachlose, Drogenabhängige), selten auftretende Merkmale, Käufer-Verkäufer-Paare in der industriellen Forschung.
QUESTIONSTAR · Dr. Paul Marx127 / 274
Kapitel 4Sektionsübersicht
4
Kapitel
Stichproben
4.1Nicht-zufällige Stichproben
4.2Zufällige Stichproben
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.2 · Zufällige StichprobenSetzt Wissen über die Grundgesamtheit voraus
Einfache und systematische Zufallsstichproben
Einfache Zufallsstichproben
Jedes Element wird unabhängig von allen anderen ausgewählt. Das bedeutet:
Jedes Element der Grundgesamtheit hat eine bekannte und gleiche Wahrscheinlichkeit, ausgewählt zu werden.
Jede mögliche Stichprobe der Größe n hat eine bekannte Wahrscheinlichkeit, tatsächlich gezogen zu werden.
Wähle zufällig
AbolinaTirza
BernhardtCarina
BerzHelena
BoeckNicola
DollaseMiriam
FränzelCarolin
FrostAnnika
GoetzeAnika
JähelFelix
JankNadja
KeitzlInga
KroppJanine
KubitzkyVictoria
LangenEduard
Systematische Zufallsstichproben
Zunächst wird ein Startelement zufällig ausgewählt; anschließend wird jedes i-te Element aus dem Stichprobenplan gezogen.
Der Abstand i ergibt sich aus dem Umfang der Grundgesamtheit N zum Umfang der Stichprobe n: i = N / n
Starte hier, dann jedes i-te
AbolinaTirza
iBernhardtCarina
BerzHelena
BoeckNicola
iDollaseMiriam
FränzelCarolin
FrostAnnika
iGoetzeAnika
GrothCarolin
JähelFelix
iJankNadja
KeitzlInga
KroppJanine
KubitzkyVictoria
QUESTIONSTAR · Dr. Paul Marx130 / 274
4.2 · Zufällige StichprobenSetzt Wissen über die Grundgesamtheit voraus
Geschichtete Zufallsstichproben
11012
246
7811
359
→
Stichprobe
210
85
Die Grundgesamtheit wird zunächst in nicht-überlappende Schichten (Stratas) aufgeteilt. Anschließend wird aus jeder Schicht ein (dis-)proportionaler Anteil zufällig gezogen. Elemente einer Schicht sollten einander ähnlich sein.
Gut für
Hervorheben einer bestimmten Subgruppe in der GrundgesamtheitBeobachtung von Zusammenhängen zwischen zwei oder mehr SubgruppenRepräsentative Ziehung auch kleinster und unzugänglichster SubgruppenHöhere statistische Genauigkeit
Proportioniert
Schicht
A
B
C
Umfang der Grundgesamtheit
100
200
300
Stichprobenanteil
½
½
½
Stichprobengröße
50
100
150
Disproportioniert
Schicht
A
B
C
Umfang der Grundgesamtheit
100
200
300
Stichprobenanteil
⅕
½
⅓
Stichprobengröße
20
100
100
QUESTIONSTAR · Dr. Paul Marx131 / 274
4.2 · Zufällige StichprobenSetzt Wissen über die Grundgesamtheit voraus
Klumpenstichproben auch Cluster-Stichproben
123456789101112
Aufteilung der Grundgesamtheit
→
561112
Stichprobe — 2 Cluster
Die Grundgesamtheit wird in exklusive Klumpen (Cluster) aufgeteilt. Anschließend werden zufällig ganze Cluster ausgewählt, die im vollen Umfang in die Stichprobe gelangen.
Pro Cluster werden entweder alle Elemente (einstufig) oder eine zufällige Teilstichprobe (zweistufig) gezogen.
Gut für
Abdecken großer geographischer GebieteReduktion von (Umfrage-)KostenWenn eine vollständige Elementliste schwer zu erstellen istWenn die Grundgesamtheit aus natürlichen Clustern besteht (Blöcke, Städte, Schulen, Krankenhäuser …)
QUESTIONSTAR · Dr. Paul Marx132 / 274
Kapitel 4Sektionsübersicht
4
Kapitel
Stichproben
4.1Nicht-zufällige Stichproben
4.2Zufällige Stichproben
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.4Größe der Stichprobe
QUESTIONSTAR · Dr. Paul Marx133 / 274
4.3 · Wahl zwischen zufälligen und nicht-zufälligen StichprobenGegenüberstellung aller Verfahren
Stärken und Schwächen von Stichproben-Auswahlverfahren
Verfahren
Stärken
Schwächen
Nicht-zufällige Auswahlverfahren
Willkürliche Auswahl
Am günstigsten, am wenigsten zeitaufwendig, am bequemsten
Fehlerbehaftet, nicht repräsentativ; nicht empfohlen für deskriptive und kausale Forschung
Bewusste Auswahl
Niedrige Kosten, bequem, nicht zeitaufwendig
Subjektiv, Ergebnisse nicht verallgemeinerbar
Quotenplan
Bestimmte Charakteristiken der Stichprobe können kontrolliert werden
Fehlerbehaftet, keine Garantie der Repräsentativität
Schneeball-Verfahren
Ermöglicht Einschätzung seltener Eigenschaften
Zeitaufwendig in der Feldforschung
Zufällige Auswahlverfahren
Einfache Zufallsstichproben
Leicht verständlich; verallgemeinerbare bzw. repräsentative Ergebnisse
Stichprobenplan schwer zu konstruieren, teuer, geringere Genauigkeit; keine Garantie der Repräsentativität
Systematische Zufallsstichproben
Kann Repräsentativität erhöhen; einfacher umzusetzen als einfache Zufallsauswahl
Kann die Repräsentativität abschwächen
Geschichtete Zufallsstichproben
Enthält alle wichtigen Subgruppen der Grundgesamtheit; hohe Genauigkeit
Relevante Aufteilungskriterien schwer auszuwählen; mehrere Kriterien nicht praktikabel; teuer
Klumpenstichproben
Einfach umzusetzen, kosteneffizient
Ungenau; komplizierte Berechnung und Interpretation der Ergebnisse
QUESTIONSTAR · Dr. Paul Marx134 / 274
Kapitel 4Sektionsübersicht
4
Kapitel
Stichproben
4.1Nicht-zufällige Stichproben
4.2Zufällige Stichproben
4.3Wahl zwischen zufälligen und nicht-zufälligen Stichproben
4.4Größe der Stichprobe
QUESTIONSTAR · Dr. Paul Marx135 / 274
4.4 · Größe der StichprobeQualitative Aspekte statt Populationsgröße
Bestimmung der Stichprobengröße
Die Stichprobengröße hängt nicht von der Größe der Grundgesamtheit ab — sie wird durch die qualitativen Aspekte der Studie bestimmt:
1
Gewünschte Genauigkeit der Vorhersagen
2
Kenntnis über die Parameter der Grundgesamtheit
3
Anzahl von Variablen
4
Typ der Analyse
5
Wichtigkeit der Entscheidung
6
Rücklauf- und Abbruchsquoten
7
Ressourceneinschränkungen
QUESTIONSTAR · Dr. Paul Marx136 / 274
4.4 · Größe der StichprobeRichtwerte aus der Praxis
Typische Stichprobengrößen in der Marktforschung
Typ der Studie
Minimaler Umfang
Typischer Umfang
Problemidentifizierungs-Studien (z. B. Marktpotenzial)
500
1.000 – 2.000
Problemlösungs-Studien (z. B. Preissetzung)
200
300 – 500
Produkttests
200
300 – 500
Studien auf den Testmärkten
200
300 – 500
TV-/Radio-/Print-Werbung (pro Anzeige)
150
200 – 300
Audit von Test-Märkten
10 Geschäfte
10 – 20 Geschäfte
Focus-Gruppen
6 Gruppen
10 – 15 Gruppen
QUESTIONSTAR · Dr. Paul Marx137 / 274
4.4 · Größe der StichprobeVom Ergebnis zur Genauigkeitsfrage
Ein Umfrageergebnis — und wie sicher ist es?
„Aus welchen Quellen beziehen Sie bevorzugt Ihre Informationen?" (n = 48.804)
Social Media32 %
Suchmaschinen24 %
News-Apps & Online-Portale18 %
Fernsehen12 %
Freunde & Bekannte9 %
Print (Zeitung/Magazin)5 %
32 %
nennen Social Media als Haupt-Informationskanal.
Aber wie nah ist dieser Wert am wahren Wert in der Grundgesamtheit?
Die Antwort liefert die Fehlerspanne — und sie bestimmt den nötigen Stichprobenumfang.
QUESTIONSTAR · Dr. Paul Marx138 / 274
4.4 · Größe der StichprobeDefinition
Ansatz der Fehlerspanne zur Bestimmung des Stichprobenumfangs
Fehlerspanne
Fehlerspanne ist das Maß der Genauigkeit einer Umfrage.
Je kleiner die Fehlerspanne, desto genauer sind die Schätzungen der Umfrage.
Ergebnis mit Fehlerspanne
31,55 %
32,45 %
32 %
Fehlerspanne ± 0,45 Prozentpunkte
QUESTIONSTAR · Dr. Paul Marx139 / 274
4.4 · Größe der StichprobeFehlerspanne berechnen
Ansatz der Fehlerspanne: zwei Formeln
x = echter Wert des Parametersx̂ = StichprobenwertE = Fehlerspanne
Für metrische Daten
Mittelwerte
Beurteilung der auf der Stichprobe errechneten Mittelwerte
zz-Wert für das vorgegebene Vertrauensniveau
σStandardabweichung des Parameters in der Grundgesamtheit
Berechnungen zeigen approximierte Werte für 95 % Vertrauensniveau
QUESTIONSTAR · Dr. Paul Marx150 / 274
4.4 · Größe der StichprobeBegriffe
Konfidenzintervall und Vertrauensniveau
Konfidenzintervall
Ein geschätzter Zahlenbereich zusammen mit der Angabe der Wahrscheinlichkeit, dass dieser Bereich den unbekannten Parameterwert enthält.
Vertrauensniveau
Der erwartete Anteil der Intervalle, die bei vielen Stichprobenziehungen den Parameterwert enthalten.
Beispiel · Arbeitsstunden
Stichprobe von 30 Personen → Ø 7,5 h. Konfidenzintervall: 7,2 – 7,8 h (Fehlerspanne ± 0,3).
95 % Vertrauensniveau heißt: Würde man die Messung 100-mal mit neuen Stichproben wiederholen, läge der echte Durchschnitt in 95 Fällen in diesem Bereich.
Viele Stichproben · 95 % treffen μ
Jeder Balken = ein Konfidenzintervall. Rot = verfehlt den wahren Wert.
QUESTIONSTAR · Dr. Paul Marx151 / 274
4.4 · Größe der StichprobeZusammenhang
Konfidenzintervall, Fehlerspanne und Stichprobenumfang
Je höhere Sicherheit (Vertrauenswahrscheinlichkeit) wir brauchen, desto breiter wird das Konfidenzintervall — und desto höher die Fehlerspanne.
1,96
für 95 %
→ Fehlerspanne ≈ 1 / √n
2,58
für 99 %
→ Fehlerspanne ≈ 1,29 / √n
Mehr Sicherheit → größerer z-Wert → für dieselbe Genauigkeit braucht man eine größere Stichprobe.
95 %
99 %
QUESTIONSTAR · Dr. Paul Marx152 / 274
4.4 · Größe der StichprobeZum Mitnehmen
Was die Fehlerspanne-Formel uns sagt
n ↑
senkt E
z ↑
hebt E
1
Der einzige Hebel, um die Fehlerspanne zu senken, ist ein größeres n — alles andere ist vorgegeben.
2
Mehr Sicherheit heißt größeres z → die Fehlerspanne wächst → man braucht ein noch größeres n, um sie wieder zu drücken.
Diskrete Variable ist eine quantitative Variable, die entweder eine endliche Anzahl von Werten oder eine unendlich abzählbare Anzahl von Werten (z. B. 0, 1, 2, 3, …) hat.
Manchmal gibt es zu viele Werte, um für jeden Wert eine Zeile zu erstellen. Dann fasst man mehrere Werte zu Gruppen (Klassen) zusammen.
Beziehung zwischen Standardabweichung und Normalverteilung
99,7% der Daten liegen innerhalb 3 Standardabweichungen vom Mittelwert
95% innerhalb 2 Standardabweichungen
68% innerhalb 1 Standard- abweichung
QUESTIONSTAR · Dr. Paul Marx175 / 274
Kapitel 5 · DatenanalyseSektionsübersicht
5
Kapitel
Datenanalyse
5.1Deskriptive Statistik: Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik: Übertragbarkeit auf die Grundgesamtheit
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
QUESTIONSTAR · Dr. Paul Marx176 / 274
5.1.4 · KreuztabellenWas & wozu
Kreuztabellen
i
Kreuztabellen
Kreuztabellen fassen die gemeinsame Verteilung von zwei (oder mehr) diskreten Variablen tabellarisch zusammen.
Sie helfen, den Zusammenhang einer Variablen (z. B. Markentreue) mit einer anderen (z. B. Geschlecht) zu analysieren.
Jede Zelle steht für eine Kombination der Ausprägungen.
Typische Fragestellungen, die eine Kreuztabelle beantwortet:
Wie viele markentreue Konsumenten sind Männer?
Hängt die Nutzungshäufigkeit (hoch, mittel, niedrig) eines Produkts mit Outdoor-Aktivitäten (oft, manchmal, selten, nie) zusammen?
Hängt die Vertrautheit mit einem neuen Produkt mit Alter und Bildungsniveau zusammen?
Hängt der Besitz eines Produkts mit dem Einkommen (hoch, mittel, niedrig) zusammen?
QUESTIONSTAR · Dr. Paul Marx177 / 274
5.1.4 · KreuztabellenBeispiel: zwei Variablen
Kreuztabellen
Hängt der Besitz von teuren Automarken vom Bildungsgrad ab?
Besitz von teuren Automarken nach Bildungsgrad
Besitz eines teuren Autos
Bildungsgrad
Hochschulabschluss
Kein Hochschulabschluss
ja
32 %
21 %
nein
68 %
79 %
Gesamt
100 %
100 %
Anzahl der Fälle
250
750
QUESTIONSTAR · Dr. Paul Marx178 / 274
5.1.4 · KreuztabellenDie dritte Variable
Kreuztabellen
Manchmal kann die Einführung einer dritten Variable aufdecken …
Fall 1Scheinbare BeziehungenDer scheinbare Zusammenhang löst sich auf, sobald man kontrolliert.
Fall 2Verdeckte ZusammenhängeEin zuvor unsichtbarer Zusammenhang wird sichtbar.
Fall 3Keine VeränderungDie ursprüngliche Beziehung bleibt unverändert bestehen.
QUESTIONSTAR · Dr. Paul Marx179 / 274
5.1.4 · KreuztabellenFall 1 · die dritte Variable
Kreuztabellen
Fall 1Scheinbare Beziehung
Hängt der Besitz von teuren Automarken vom Bildungsgrad ab?
Besitz von teuren Automarken nach Bildungsgrad und Einkommensniveau
Besitz eines teuren Autos
Hohes Einkommen
Geringes Einkommen
Hochschulabschluss
Kein Hochschulabschluss
Hochschulabschluss
Kein Hochschulabschluss
ja
20 %
20 %
40 %
40 %
nein
80 %
80 %
60 %
60 %
Gesamt
100 %
100 %
100 %
100 %
Anzahl der Fälle
100
700
150
50
Ist die Beziehung noch da?
Nein — innerhalb jeder Einkommensgruppe ist der Autobesitz gleich (20 % bzw. 40 %). Der Zusammenhang mit dem Bildungsgrad war scheinbar; tatsächlich wirkt das Einkommen.
QUESTIONSTAR · Dr. Paul Marx180 / 274
5.1.4 · KreuztabellenFall 2 · die dritte Variable
Kreuztabellen
Fall 2Verdeckter Zusammenhang
Hat Alter Einfluss auf Reise- und Abenteuerlust?
Verlangen nach Auslandsreisen nach Alter
Verlangen nach Auslandsreisen
Alter
Unter 45
45 und mehr
ja
50 %
50 %
nein
50 %
50 %
Gesamt
100 %
100 %
Anzahl der Fälle
500
500
… nach Alter und Geschlecht
Verlangen nach Auslandsreisen
Männlich
Weiblich
< 45
≥ 45
< 45
≥ 45
ja
60 %
40 %
35 %
65 %
nein
40 %
60 %
65 %
35 %
Gesamt
100 %
100 %
100 %
100 %
Anzahl der Fälle
300
300
200
200
Aggregiert (50 %/50 %) scheint Alter keine Rolle zu spielen. Erst getrennt nach Geschlecht zeigt sich: bei Männern steigt, bei Frauen sinkt die Reiselust mit dem Alter — ein verdeckter Zusammenhang.
QUESTIONSTAR · Dr. Paul Marx181 / 274
5.1.4 · KreuztabellenFall 3 · die dritte Variable
Kreuztabellen
Fall 3Keine Veränderung
Hängt die Besuchshäufigkeit von Fast-Food-Restaurants mit der Familiengröße zusammen?
Besuchshäufigkeit nach Familiengröße
Gehen häufig in Fast-Food-Restaurants
Familiengröße
Small
Large
ja
50 %
50 %
nein
50 %
50 %
Gesamt
100 %
100 %
Anzahl der Fälle
500
500
… nach Familiengröße und Einkommen
Gehen häufig in Fast-Food-Restaurants
Geringes Einkommen
Hohes Einkommen
Small
Large
Small
Large
ja
50 %
50 %
50 %
50 %
nein
50 %
50 %
50 %
50 %
Gesamt
100 %
100 %
100 %
100 %
Anzahl der Fälle
250
250
250
250
Auch nach Einführung der dritten Variable (Einkommen) bleibt überall 50 %/50 % — die ursprüngliche (Nicht-)Beziehung ändert sich nicht.
QUESTIONSTAR · Dr. Paul Marx182 / 274
Kapitel 5 · DatenanalyseSektionsübersicht
5
Kapitel
Datenanalyse
5.1Deskriptive Statistik: Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik: Übertragbarkeit auf die Grundgesamtheit
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
QUESTIONSTAR · Dr. Paul Marx183 / 274
Kapitel 5 · DatenanalyseSektionsübersicht
5
Kapitel
Datenanalyse
5.1Deskriptive Statistik: Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik: Übertragbarkeit auf die Grundgesamtheit
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
QUESTIONSTAR · Dr. Paul Marx184 / 274
5.2.1 · HypothesentestWas & Ablauf
Hypothesentest
i
Hypothesentest
Ein fünfstufiges Verfahren, das auf Basis einer Stichprobe und mithilfe der Wahrscheinlichkeitstheorie bestimmt, ob eine Hypothese hinreichend begründet ist.
Anders gesagt: eine Methode zu prüfen, ob sich die Ergebnisse einer Zufallsstichprobe auf die Grundgesamtheit übertragen lassen.
Vorgehensweise in fünf Schritten:
Formulierung einer Nullhypothese und ihrer Alternativhypothese
Festlegen des Signifikanzniveaus
Wahl der geeigneten Teststatistik
Formulierung der Entscheidungsregel
Berechnung der Kennzahlen aus der Stichprobe und Treffen der Entscheidung
„Menschen sind sich irrtümlicherweise zuversichtlich in ihrem Wissen und unterschätzen die Wahrscheinlichkeit, dass ihre Überzeugungen sich als falsch erweisen. Sie neigen dazu, nur solche Informationen zu suchen, die bestätigen, was sie ohnehin schon glauben."— Max Bazerman
QUESTIONSTAR · Dr. Paul Marx185 / 274
5.2.1 · HypothesentestAusgangsbeispiel
Hypothesentest
Nutzen Männer wirklich häufiger das Internet als Frauen — in der ganzen Bevölkerung?
Internetnutzung und Geschlecht · Stichprobe n = 30
Internetnutzung
Geschlecht
Gesamt
Männlich
Weiblich
selten
5
10
15
häufig
10
5
15
Gesamt
15
15
n = 30
In der Stichprobe nutzen Männer häufiger das Internet. Aber gilt das auch in der Grundgesamtheit — oder ist es Zufall der Stichprobe?
QUESTIONSTAR · Dr. Paul Marx186 / 274
5.2.1 · HypothesentestSchritt 1 · Hypothesen
Hypothesentest
Schritt 1 · Formulierung einer Nullhypothese und ihrer Alternativhypothese
H₀Es gibt keinen Unterschied zwischen Männern und Frauen bei der Häufigkeit der Internetnutzung.
H₁Männer und Frauen zeigen unterschiedliches Internetnutzungsverhalten.
Nullhypothese (H₀) ist eine Behauptung des Status quo — dass es keinen Unterschied bzw. keinen Effekt gibt.
Alternativhypothese (H₁) behauptet das Gegenteil — dass es einen Unterschied bzw. einen Effekt gibt.
QUESTIONSTAR · Dr. Paul Marx187 / 274
5.2.1 · HypothesentestSchritt 2 · Fehlerarten
Hypothesentest
Schritt 2 · Festlegen vom Signifikanzniveau
Signifikanz (α) — Wahrscheinlichkeit, dass eine wahre Nullhypothese zurückgewiesen wird.
β — Wahrscheinlichkeit, dass eine falsche Nullhypothese angenommen wird.
fe — Häufigkeiten, die wir in den Zellen erwarten würden, wenn es keinen Zusammenhang gäbe.
fo — tatsächlich beobachtete Häufigkeiten.
fe = nr · ncn
nr — Gesamtsumme in einer Zeile
nc — Gesamtsumme in einer Spalte
n — Umfang der Stichprobe
fe₁,₁ = 15 · 1530 = 7,5
fe₁,₂ = 15 · 1530 = 7,5
fe₂,₁ = 15 · 1530 = 7,5
fe₂,₂ = 15 · 1530 = 7,5
QUESTIONSTAR · Dr. Paul Marx195 / 274
5.2.1 · HypothesentestSchritt 3 · χ²-Berechnung
Hypothesentest
fe — Häufigkeiten, die wir in den Zellen erwarten würden, wenn es keinen Zusammenhang gäbe.
fo — tatsächlich beobachtete Häufigkeiten.
Schritt 3 · Wahl der geeigneten Teststatistik
χ² sollte immer nur mit absoluten Häufigkeiten berechnet werden. Liegen die Daten in Prozent (relative Häufigkeiten) vor, müssen sie zuvor in absolute Häufigkeiten umgerechnet werden.
TScal — beobachteter (berechneter) Wert der Teststatistik.
TScr — kritischer Wert der Teststatistik für das gewählte Signifikanzniveau.
Wenn die Wahrscheinlichkeit von TScal < Signifikanzniveau (α), dann lehne H₀ ab.
oder
Wenn TScal > TScr, dann weise H₀ zurück.
QUESTIONSTAR · Dr. Paul Marx197 / 274
5.2.1 · HypothesentestSchritt 4 · Vergleich
Hypothesentest
Schritt 4 · Formulierung der Entscheidungsregel
Kritische Werte von χ² für verschiedene Signifikanzniveaus α
df
0,99
0,975
0,95
0,90
0,10
0,05
0,025
0,01
1
—
0,001
0,004
0,016
2,706
3,841
5,024
6,635
2
0,020
0,051
0,103
0,211
4,605
5,991
7,378
9,210
3
0,115
0,216
0,352
0,584
6,251
7,815
9,348
11,345
4
0,297
0,484
0,711
1,064
7,779
9,488
11,143
13,277
5
0,554
0,831
1,145
1,610
9,236
11,071
12,833
15,086
6
0,872
1,237
1,635
2,204
10,645
12,592
14,449
16,812
7
1,239
1,690
2,167
2,833
12,017
14,067
16,013
18,475
8
1,646
2,180
2,733
3,490
13,362
15,507
17,535
20,090
9
2,088
2,700
3,325
4,168
14,684
16,919
19,023
21,666
10
2,558
3,247
3,940
4,865
15,987
18,307
20,483
23,209
df = (r−1)(c−1)
df — Freiheitsgrade
r — Anzahl von Zeilen
c — Anzahl von Spalten
df = (2−1)(2−1) = 1
Wenn die Wahrscheinlichkeit von TScal < (α), dann lehne H₀ ab.
oder
Wenn TScal > TScr, dann weise H₀ zurück.
χ²cal = 3,333
χ²cr = 3,841
3,333 < 3,841 ⟹ χ²cal < χ²cr
H₀ kann NICHT zurückgewiesen werden
QUESTIONSTAR · Dr. Paul Marx198 / 274
5.2.1 · HypothesentestSchritt 5 · Entscheidung
Hypothesentest
Schritt 5 · Treffen der Entscheidung
Ist der Beweis da?
Was sind die Konsequenzen?
H₀ — dass es keinen Zusammenhang gibt — kann nicht zurückgewiesen werden.
Der Zusammenhang ist auf dem Signifikanzniveau von 0,05 statistisch nicht signifikant.
Die aus der Stichprobe beobachteten Ergebnisse können nicht auf die Grundgesamtheit verallgemeinert werden.
QUESTIONSTAR · Dr. Paul Marx199 / 274
5.2.1 · HypothesentestFazit zum Beispiel
Hypothesentest
Internetnutzung und Geschlecht · n = 30
Internetnutzung
Geschlecht
Gesamt
Männlich
Weiblich
selten
5
10
15
häufig
10
5
15
Gesamt
15
15
n = 30
Nutzen Männer wirklich häufiger das Internet als Frauen — in der Grundgesamtheit?
Antwort: Die Stichprobe erbringt dafür keine Beweise.
Wenn die Stichprobe sorgfältig ausgewählt und gezogen wurde, können wir mit 95 % Vertrauenswahrscheinlichkeit behaupten, dass es keinen solchen Zusammenhang gibt.
Ansonsten — wir wissen es nicht.
QUESTIONSTAR · Dr. Paul Marx200 / 274
Kapitel 5 · DatenanalyseSektionsübersicht
5
Kapitel
Datenanalyse
5.1Deskriptive Statistik: Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik: Übertragbarkeit auf die Grundgesamtheit
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
QUESTIONSTAR · Dr. Paul Marx201 / 274
5.2.2 · Stärke des ZusammenhangsÜbersicht
Prüfung der Stärke des Zusammenhangs
χ² prüft nur die Signifikanz eines Zusammenhangs und trifft keine Aussage über seine Stärke.
Einfacher Nachweis: Verdoppelung aller Werte in der Kreuztabelle führt zur Verdoppelung von χ² — der Zusammenhang selbst bleibt aber gleich.
Maße für die Stärke des Zusammenhangs sind:
φ
Phi-Koeffizient
C
Kontingenzkoeffizient
V
Cramers V
λ
Lambda-Koeffizient
QUESTIONSTAR · Dr. Paul Marx202 / 274
5.2.2 · Stärke des ZusammenhangsPhi-Koeffizient
Phi-Koeffizient
Je höher φ, desto stärker ist der Zusammenhang zwischen den Variablen.
Werte > 0,30 werden als substantiell angesehen.
Probleme:
φ ist nicht standardisiert und hat eine Obergrenze von 1 nur für 2×2-Tabellen; sie hängt von den Tabellendimensionen ab.
φ-Werte aus verschiedenen Studien können nicht miteinander verglichen werden.
In unserem Beispiel:
Der Zusammenhang ist nicht besonders stark.
QUESTIONSTAR · Dr. Paul Marx203 / 274
5.2.2 · Stärke des ZusammenhangsKontingenzkoeffizient
Kontingenzkoeffizient
Je höher C, desto stärker ist der Zusammenhang zwischen den Variablen.
Werte > 0,30 werden als substantiell angesehen.
Obwohl C-Werte die Obergrenze von 1 haben, können sie diese Grenze faktisch nicht erreichen.
Probleme:
C ist nicht standardisiert und hängt von den Tabellendimensionen ab.
C-Werte aus verschiedenen Studien können nicht miteinander verglichen werden.
In unserem Beispiel:
Der Zusammenhang ist nicht besonders stark.
QUESTIONSTAR · Dr. Paul Marx204 / 274
5.2.2 · Stärke des ZusammenhangsCramers V
Cramers V
r — Anzahl von Zeilen
c — Anzahl von Spalten
Je höher V, desto stärker ist der Zusammenhang zwischen den Variablen.
Werte > 0,30 werden als substantiell angesehen.
V-Werte haben die Obergrenze von 1, können sie aber ebenfalls faktisch nur bei 2×2-Tabellen erreichen.
Probleme:
V ist nicht standardisiert und hängt von den Tabellendimensionen ab.
V-Werte aus verschiedenen Studien können nicht miteinander verglichen werden.
In unserem Beispiel:
Der Zusammenhang ist nicht besonders stark.
QUESTIONSTAR · Dr. Paul Marx205 / 274
5.2.2 · Stärke des ZusammenhangsLambda-Koeffizient
Lambda-Koeffizient
r — Zeilenindex
c — Spaltenindex
Gibt Aufschluss darüber, inwieweit die Kenntnis der Ausprägung einer Variable bei der Prognose der anderen Variable hilft.
Ist standardisiert zwischen 0 und 1 (1 — fehlerfreie Prognose, 0 — keine Verbesserung der Vorhersage).
λ-Werte aus verschiedenen Studien können miteinander verglichen werden.
In unserem Beispiel:
Kenntnis vom Geschlecht erhöht die Prognosegenauigkeit um den Faktor 0,333, d.h. 33,3 % Verbesserung.
QUESTIONSTAR · Dr. Paul Marx206 / 274
5.2.2 · Stärke des ZusammenhangsLambda · Berechnung
Lambda-Koeffizient
Summe der maximalen Häufigkeiten aller Spalten
maximaler Gesamtwert einer Zeile
r — Zeilenindex
c — Spaltenindex
Internetnutzung
Geschlecht
Gesamt (Zeile)
Männlich
Weiblich
r = 1selten
5
10
15
r = 2häufig
10
5
15
Gesamt (Spalte)
15c = 1
15c = 2
n = 30
Kenntnis vom Geschlecht erhöht die Prognosegenauigkeit um den Faktor 0,333, d.h. 33,3 % Verbesserung.
QUESTIONSTAR · Dr. Paul Marx207 / 274
Kapitel 5 · DatenanalyseSektionsübersicht
5
Kapitel
Datenanalyse
5.1Deskriptive Statistik: Darstellung und Präsentation von Daten
5.1.1Zusammenfassung qualitativer Daten
5.1.2Zusammenfassung quantitativer Daten
5.1.3Numerische Zusammenfassung von Daten
5.1.4Kreuztabellen
5.2Induktive Statistik: Übertragbarkeit auf die Grundgesamtheit
5.2.1Hypothesentest
5.2.2Stärke des Zusammenhangs in Kreuztabellen
5.2.3Beziehung zwischen zwei (metrischen) Variablen
QUESTIONSTAR · Dr. Paul Marx208 / 274
5.2.3 · Beziehung zweier VariablenTypen des Zusammenhangs
Typen vom Zusammenhang zweier Variablen
Soweit die Daten nicht aus einem kontrollierten Experiment stammen, können wir nur die Existenz einer Beziehung zwischen den Variablen behaupten — nicht jedoch die kausale Richtung dieser Beziehung.
Werte des linearen Korrelationskoeffizienten liegen immer zwischen −1 und 1.
Bei r = +1 besteht ein vollständig positiver linearer Zusammenhang zwischen den Variablen.
Bei r = −1 besteht ein vollständig negativer linearer Zusammenhang zwischen den Variablen.
Je näher r an +1 bzw. −1 liegt, desto stärker der jeweilige Zusammenhang.
Liegt r nahe 0, gibt es kaum Nachweis für einen linearen Zusammenhang — das bedeutet aber nicht, dass es gar keine Beziehung gibt, eben nur keine lineare.
i
Linearer Korrelationskoeffizient
Der (Pearsonsche) lineare Korrelationskoeffizient misst die Stärke der linearen Beziehung zwischen zwei Variablen.
Können Werbeausgaben die Absatzänderungen erklären?
Kann der Marktanteil auf die Größe der Verkaufsabteilung zurückgeführt werden?
Wird die Qualitätswahrnehmung von Konsumenten von ihrer Wahrnehmung vom Preis beeinflusst?
i
Regressionsanalyse
Die Regressionsanalyse ist ein mächtiges und flexibles Instrument zur Analyse von assoziativen Beziehungen zwischen einer metrischen abhängigen Variable und einer oder mehreren unabhängigen Variablen.
Ermöglicht:
die Existenz der Beziehung zu bestimmen,
die Stärke der Beziehung zu quantifizieren,
ein mathematisches Modell (Formel) der Beziehung abzuleiten,
Werte der abhängigen Variable vorherzusagen,
den Einfluss anderer unabhängiger Variablen zu berücksichtigen.
QUESTIONSTAR · Dr. Paul Marx213 / 274
5.2.3 · Beziehung zweier VariablenRechenbeispiel
Regressionsanalyse
Wie viele Produkteinheiten werden wir absetzen, wenn wir €85.000 für die Werbung ausgeben?
Werbeausgaben, €1.000
Absatz, €1.000
40
377
60
507
70
555
110
779
150
869
160
818
190
862
200
817
Erhobene Daten
Zusammenhang zwischen Absatz und Werbeausgaben
Werbeausgaben erklären 83,6 % der Varianz vom Absatz.
Jeder zusätzliche in die Werbung investierte Euro bringt €2,82 zusätzlichen Absatz.
Die Conjoint-Analyse ist eine Reihe von Techniken, die in der Marktforschung für die Analyse von attributbasierten Präferenzen von Konsumenten eingesetzt werden — d.h. um zu bestimmen, wie wichtig unterschiedliche Produkteigenschaften und Eigenschaftsausprägungen für die Konsumenten sind.
Wie soll unser neues Produkt aussehen?
Besonderheiten
Bewertung von ganzheitlichen Objekten
Dekomposition von Präferenzen
Stark verbreitet in
Segmentierung
Entwicklung von neuen Produkten
Preissetzung
QUESTIONSTAR · Dr. Paul Marx217 / 274
6.1 · Conjoint-AnalyseDirekte Abfrage
Conjoint-Analyse
Bitte geben Sie an, inwieweit folgende PC-Eigenschaften bei Ihrer nächsten Entscheidung über den Kauf eines PCs wichtig sind?
ganz und gar nicht wichtig
ausgesprochen wichtig
Hersteller/Marke
Prozessorleistung, GHz
Speicher, GB
Display-Größe
Preis
QUESTIONSTAR · Dr. Paul Marx218 / 274
6.1 · Conjoint-AnalyseErwartung
Conjoint-Analyse
Erwartung
Wir erwarten, dass uns die Befragten klare Unterschiede in der Wichtigkeit verraten.
Frage: „Bitte geben Sie an, inwieweit folgende PC-Eigenschaften bei Ihrer nächsten Kaufentscheidung wichtig sind?“
ganz und gar nicht wichtig
ausgesprochen wichtig
Hersteller/Marke
Prozessorleistung, GHz
Speicher, GB
Display-Größe
Preis
QUESTIONSTAR · Dr. Paul Marx219 / 274
6.1 · Conjoint-AnalyseRealität
Conjoint-Analyse
Realität
In der Realität ist den Befragten praktisch alles wichtig.
Frage: „Bitte geben Sie an, inwieweit folgende PC-Eigenschaften bei Ihrer nächsten Kaufentscheidung wichtig sind?“
ganz und gar nicht wichtig
ausgesprochen wichtig
Hersteller/Marke
Prozessorleistung, GHz
Speicher, GB
Display-Größe
Preis
QUESTIONSTAR · Dr. Paul Marx220 / 274
6.1 · Conjoint-AnalyseWarum gemeinsam beurteilen?
Conjoint-Analyse
Relative Wichtigkeiten einzelner Produkteigenschaften können besser gemessen werden, wenn sie von Probanden als einheitliches Stimulus beurteilt werden (CONsidered JOINTly), als wenn jede Eigenschaft isoliert bewertet wird:
Viele Konsumenten sind nicht in der Lage, die relative Wichtigkeit einzelner Produkteigenschaften zu bestimmen.
Einzelne Eigenschaften werden isoliert anders wahrgenommen als ihre Kombination, die ein ganzheitliches Produkt ausmacht.
Die Konstruktion der bevorzugten Eigenschaftskombination belastet die kognitiven Fähigkeiten von Probanden — „alle Eigenschaften sind wichtig“.
Soziale Erwünschtheit und scharf ausgeprägte Selbsteinschätzung motivieren Probanden, einigen Eigenschaften viel Gewicht zu geben, auch wenn sie keine Rolle spielen (z. B. Umweltfreundlichkeit, Wohlstand, verringerte Bedeutung vom Preis).
Einige Probanden versuchen absichtlich, die Ergebnisse zu manipulieren, indem sie „vorteilhafte“ Antworten geben (z. B. Überbewertung der Wichtigkeit vom Preis).
QUESTIONSTAR · Dr. Paul Marx221 / 274
6.1 · Conjoint-AnalyseWahlaufgabe
Conjoint-Analyse
Wenn Sie heute einen Laptop kaufen müssten und dies die einzig auf dem Markt verfügbaren Alternativen wären — welche Alternative würden Sie wählen?
MacBook Air
M3-Chip (8 Kerne)
16 GB Speicher
13,6″ Display
€ 1.299,–
Dell XPS 14
Core Ultra 7
32 GB Speicher
14,5″ Display
€ 1.899,–
ASUS Zenbook
Ryzen 7 (8 Kerne)
16 GB Speicher
14″ Display
€ 999,–
Keine
Wenn das die einzigen Alternativen wären, würde ich den Kauf aufschieben.
Angesichts folgender Präferenzwerte — welches Produkt sollten wir auf dem Markt anbieten?
Produktalternativen
Blau
Rot
Gelb
Proband #1
50
40
10
Proband #2
0
65
75
Proband #3
40
30
20
Mittelwert
30
45
35
QUESTIONSTAR · Dr. Paul Marx224 / 274
6.2 · MarktsimulationenDer naheliegende Schluss
Marktsimulationen
Angesichts folgender Präferenzwerte — welches Produkt sollten wir auf dem Markt anbieten?
Produktalternativen
Blau
Rot
Gelb
Proband #1
50
40
10
Proband #2
0
65
75
Proband #3
40
30
20
Mittelwert
30
45
35
„Rot" hat den höchsten durchschnittlichen Präferenzwert.
QUESTIONSTAR · Dr. Paul Marx225 / 274
6.2 · MarktsimulationenAber: die tatsächliche Wahl
Marktsimulationen
Angesichts folgender Präferenzwerte — welches Produkt sollten wir auf dem Markt anbieten?
Produktalternativen
Wahl
Blau
Rot
Gelb
Proband #1
50
40
10
Blau
Proband #2
0
65
75
Gelb
Proband #3
40
30
20
Blau
Mittelwert
30
45
35
Rot
„Rot" hat zwar den höchsten Durchschnitt — doch niemand wählt tatsächlich „Rot".
QUESTIONSTAR · Dr. Paul Marx226 / 274
6.2 · MarktsimulationenWarum? Der Wettbewerb!
Marktsimulationen
Angenommen: 80 % der Kunden bevorzugen runde Dinge, 20 % bevorzugen eckige. Welche Art von Dingen sollten wir auf den Markt bringen?
80 % runde Dinge
20 %
Ohne Zusatzinformation
Die Wahl scheint offensichtlich — gehe dahin, wo die meisten Kunden sind:
„runde Dinge"der „fette" Teil des Marktes
Was, wenn …
es bereits 10 Wettbewerber gibt, die ALLE runde Dinge anbieten?
10 Anbieter kämpfen um dieselben 80 % — die 20 % „eckig" sind völlig unbesetzt.
Erst im Kontext des Wettbewerbs zeigt sich: Der kleinere, unbesetzte Markt kann profitabler sein — genau das macht eine Marktsimulation sichtbar.
QUESTIONSTAR · Dr. Paul Marx227 / 274
6.2 · MarktsimulationenDie Vorteile
Warum Marktsimulationen?
Marktsimulationen spiegeln die Realität besser wider als rein datengetriebene Modelle — und liefern Entscheidungen, die im Wettbewerb tatsächlich tragen.
01
Näher an der Realität
bilden idiosynkratische Präferenzen von Segmenten und Individuen ab
berücksichtigen Präferenzen und konkurrierende Angebote am Markt
02
Nischen statt nur Masse
Kein Zwang, sich auf den „fetten" Teil des Marktes zu fixieren — auch unbesetzte Segmente können guten Profit bringen.
03
„Versuchslabor"
Eine Vielzahl realer Marktchancen lässt sich risikofrei durchspielen — samt ihrer möglichen Ergebnisse.
04
Aktionsfähig fürs Management
Die Ergebnisse sind leicht verständlich und lassen sich direkt in Entscheidungen übersetzen.
QUESTIONSTAR · Dr. Paul Marx228 / 274
6.2 · MarktsimulationenDer grundlegende Prozess
Was machen Marktsimulationen?
Der grundlegende Prozess läuft für jeden Probanden einzeln ab — und wird anschließend zu Marktanteilen aggregiert:
Input
Präferenzstruktur des Probanden
bekannt — z. B. aus der Conjoint-Analyse
+
Input
Erschöpfende Marktinformation
existierende und simulierte Produktangebote
→
Wahlregel
Produktwahl bzw. Auswahlwahrscheinlichkeit
pro Proband bestimmt
→
Aggregiert
Marktanteile jedes Produkts
Σ über alle Probanden
QUESTIONSTAR · Dr. Paul Marx229 / 274
6.2 · MarktsimulationenWahlregeln
Was machen Marktsimulationen?
Die Produktwahl je Proband wird durch sogenannte Wahlregeln bestimmt — z. B.:
Regel der ersten Wahl
First-Choice-Rule
Das Produkt mit dem höchsten Nutzen wird gewählt.
Auswahlwahrscheinlichkeit = 100 % für dieses Produkt, 0 % für alle anderen.
BTL-Modell
nach Bradley · Terry · Luce
Auswahlwahrscheinlichkeit hängt vom relativen Nutzenanteil am Markt ab.
Auch Produkte mit geringem Präferenz- bzw. Nutzenwert erhalten eine positive Wahrscheinlichkeit.
Logit-Regel
kontrastbasiert
Auswahlwahrscheinlichkeit steigt mit zunehmendem Kontrast im Produktnutzen.
Ermöglicht eine a-priori-Anpassung simulierter an reale Marktanteile.
Marktsegmentierung bezeichnet die Aufspaltung des „relevanten Marktes" in Gruppen von Konsumenten, die nach innen homogen und nach außen heterogen sind — und bildet die Grundlage einer differenzierten Marktbearbeitung.
Aus einer gemischten Gesamtgruppe werden in sich homogene, untereinander verschiedene Segmente.
Ziel
Entwicklung effizienter Produktdifferenzierungsstrategien — für eine möglichst optimale Ausschöpfung der Potentiale einzelner Segmente.
QUESTIONSTAR · Dr. Paul Marx232 / 274
6.3 · SegmentierungEffektivität
Effektive Marktsegmentierung
Sechs Kriterien bestimmen die Effizienz und Wirtschaftlichkeit einer Segmentlösung:
1
Identifizierbarkeit
Konsumenten lassen sich auf Basis einfach messbarer Variablen identifizieren.
2
Substantialität
Segmente müssen groß genug sein, um Investitionen amortisieren zu können.
3
Zugänglichkeit
Gezielte Ansprache bzw. gezielter Einsatz des Marketing-Mix ist möglich.
4
Stabilität
… über den Zeitraum von Planung, Durchführung und Wirkung segmentspezifischer Maßnahmen.
5
Verhaltensrelevanz
Einheitliche Reaktion auf segmentspezifische Maßnahmen (z. B. Preisänderung).
6
Handlungsfähigkeit
Sinnvoll und hilfreich bei der Formulierung des Marketing-Mix.
QUESTIONSTAR · Dr. Paul Marx233 / 274
6.3 · SegmentierungTypologie der Merkmale
Typologie von Segmentierungsmerkmalen
Generell
Produktspezifisch
Beobachtbar
Kulturelle Merkmale
Geographische Merkmale
Demographische Merkmale
Sozioökonomische Merkmale
Nutzerstatus & Nutzungssituation
Nutzungshäufigkeit & -intensität
Markentreue & -loyalität
Nicht beobachtbar
Psychographische Merkmale
Werte
Persönlichkeit & Lifestyle
Nutzenvorstellungen / Produktnutzen
Einstellungen & Wahrnehmung
Präferenzen, Motive & Absichten
QUESTIONSTAR · Dr. Paul Marx234 / 274
6.3 · SegmentierungNutzen-Segmentierung
Nutzen-Segmentierung
Der Nutzen, den Konsumenten von Produkten erwarten, gilt als eines der relevantesten Segmentierungsmerkmale überhaupt:
… Der Nutzen, den Menschen von Produkten erwarten, ist einer der Hauptgründe für die Heterogenität in ihrem Wahlverhalten. Somit ist der Nutzen das relevanteste Segmentierungsmerkmal.
— Haley, 1968
… Nutzen ist eines der beliebtesten Merkmale der Segmentierung — zwecks Marktverständnis, Positionierung, Entwicklung neuer Produktkonzepte sowie Werbe- und Vertriebsstrategien. Das alles aufgrund seiner Aktionsfähigkeit.
— Wind, 1978
QUESTIONSTAR · Dr. Paul Marx235 / 274
6.3 · SegmentierungBewertung der Merkmale
Bewertung von Segmentierungsmerkmalen
Merkmalstyp
Identifizier- barkeit
Substan- tialität
Zugäng- lichkeit
Stabilität
Handlungs- fähigkeit
Verhaltens- relevanz
1 · Generelle, beobachtbare
++
++
++
++
–
–
2 · Spezifische, beobachtbare
Kauf
+
++
–
+
–
+
Nutzung
+
++
+
+
–
+
3 · Generelle, nicht beobachtbare
Persönlichkeit
±
–
±
±
–
–
Lifestyle
±
–
±
±
–
–
Psychographische Merkmale
±
–
±
±
–
–
4 · Spezifische, nicht beobachtbare
Psychographische Merkmale
±
+
–
–
++
±
Wahrnehmung
±
+
–
–
+
–
Nutzen bzw. Nutzenvorstellungen
+
+
–
+
++
++
Absichten
+
+
–
±
–
++
Markiert — die in der Praxis aussichtsreichsten Merkmale: In Kombination decken sie die Segmentierungskriterien am besten ab.
Stamm = Gesamtmittel über alle BefragtenAst (gestrichelt) = Cluster-Mittel ± 1 StandardabweichungReihenfolge oben → unten: F-Ratio absteigend (oben am besten trennend)Schematische Darstellung zur Veranschaulichung des Prinzips
Oben stehen die Merkmale mit der höchsten F-Ratio — kleine Streuung, klare Lage zum Stamm: Sie trennen die Segmente am besten. Nach unten wächst die Streuung, die Cluster überlappen — die Trennkraft sinkt.
QUESTIONSTAR · Dr. Paul Marx237 / 274
6.3 · SegmentierungParadox
Paradox der Nutzensegmentierung
Bei der Segmentierung nach erwartetem Nutzen muss man klar zwischen zwei Typen von Variablen unterscheiden:
Typ (i) · Trennen
Diskriminierende Variablen
Wichtig, um die Stichprobe in nach innen homogene Segmente zu trennen.
Typ (ii) · Verstehen
Treiber-Variablen
Wichtig, weil sie den Nutzen bzw. die Eigenschaften darstellen, die Probanden je Segment am meisten verlangen.
Es ist verlockend anzunehmen, beide seien dasselbe. Manchmal ja — meistens jedoch nicht: Die „Treiber" variieren oft gar nicht zwischen den Segmenten und besitzen keine Diskriminanzkraft (z. B. Preis, Qualität).
Positionierung richtet alle Marketingaktivitäten an den Präferenzstrukturen der potenziellen Kunden aus — unter Berücksichtigung der Wettbewerbsprodukte.
Ziel: die Unternehmensleistungen so zu gestalten, dass die von Kunden wahrgenommenen Ist-Eigenschaften mit den gewünschten Soll-Eigenschaften in Übereinstimmung gebracht werden.
Wie der rote Apfel zwischen grünen: eine klar unterscheidbare Position.
QUESTIONSTAR · Dr. Paul Marx240 / 274
6.4 · WahrnehmungskartenRolle der Wahrnehmung
Die Rolle der Wahrnehmung
Dieselben Probanden, dieselben Colas — nur das Wissen um die Marke ändert sich. Die Präferenz kippt:
Blindtest
Probanden wissen nicht, welche Cola sie trinken
Diet Pepsi
51 %
Diet Coke
44 %
Keine Präferenz
5 %
„Offener" Test
Probanden wissen, welche Cola sie trinken
Diet Pepsi
23 %
Diet Coke
65 %
Keine Präferenz
12 %
Blind gewinnt Pepsi — mit Markenwissen gewinnt Coke. Nicht das Produkt entscheidet, sondern die Wahrnehmung.
QUESTIONSTAR · Dr. Paul Marx241 / 274
6.4 · WahrnehmungskartenGrundbegriff
Wahrnehmungskarten
Budget
Hochwertig
Stark
Leicht
Arbeiter
Vollmundig
Stark
Populär unter Männern
Zum besonderen Anlass
Auswärts essen
Hochwertig
Gutes Preis- Leistungs-Verhältnis
Günstig
Hell
Leicht
Nicht sättigend
Populär unter Frauen
Wahrnehmungskarten bilden die Positionen konkurrierender Produkte, Marken oder Unternehmen in einem „virtuellen" Eigenschaftsraum ab — so, wie Konsumenten die gesamte Produktkategorie wahrnehmen.
Achsen
Die latenten Produkteigenschaften, die zwischen allen Alternativen am besten differenzieren.
Vektoren
Geben Richtung und Stärke wahrgenommener Produkteigenschaften an.
Abstände
Zwischen zwei Alternativen entsprechen dem Grad ihrer wahrgenommenen (Un-)Ähnlichkeit.
QUESTIONSTAR · Dr. Paul Marx242 / 274
6.4 · WahrnehmungskartenZiel der Positionierung
Ziel der Positionierung
Ziel der Positionierung ist es, in der Wahrnehmung von Konsumenten eine solche Position einzunehmen, die:
möglichst nah am Idealpunkt und
möglichst weit weg von der Konkurrenz ist.
Jede Achse ist eine latente Eigenschaft; jedes Produkt nimmt eine wahrgenommene Position ein.
QUESTIONSTAR · Dr. Paul Marx243 / 274
6.4 · WahrnehmungskartenBeispiel: Sessel-Designs
Wahrnehmungskarte von Sessel-Designs
Kompliziert
Emotional
Übertrieben
Leicht
Modern
Einfach
Rational
Realistisch
Schwer
Traditionell
Quelle: Chuang & Chen (2008), International Journal of Design
QUESTIONSTAR · Dr. Paul Marx244 / 274
6.4 · WahrnehmungskartenBeispiel: Biermarken
Wahrnehmungskarten
Budget
Hochwertig
Stark
Leicht
Arbeiter
Vollmundig
Stark
Populär unter Männern
Zum besonderen Anlass
Auswärts essen
Hochwertig
Gutes Preis- Leistungs-Verhältnis
Günstig
Hell
Leicht
Nicht sättigend
Populär unter Frauen
Quelle: Moore / Pessemier (1993), S. 145
QUESTIONSTAR · Dr. Paul Marx245 / 274
6.4 · WahrnehmungskartenWettbewerbsintensität
Wahrnehmungskarten
Wettbewerbsintensität
Je näher die Marken sind, desto ähnlicher sind sie in der Wahrnehmung der Konsumenten — desto stärker („direkter") ist der Wettbewerb.
Budget
Hochwertig
Stark
Leicht
Arbeiter
Vollmundig
Stark
Populär unter Männern
Zum besonderen Anlass
Auswärts essen
Hochwertig
Gutes Preis- Leistungs-Verhältnis
Günstig
Hell
Leicht
Nicht sättigend
Populär unter Frauen
Relativ starke Konkurrenz
Gleiche Distanz = ähnliche Wettbewerbsintensität
Relativ schwache Konkurrenz
QUESTIONSTAR · Dr. Paul Marx246 / 274
6.4 · WahrnehmungskartenEigenschaftsvektoren
Wahrnehmungskarten
Eigenschaftsvektoren
Wahrnehmung von Brands durch Konsumenten: Je weiter ein Brand vom Ursprung entlang eines Eigenschaftsvektors entfernt ist, desto stärker ist diese Eigenschaft bei ihm ausgeprägt.
Budget
Hochwertig
Stark
Leicht
Arbeiter
Vollmundig
Stark
Populär unter Männern
Zum besonderen Anlass
Auswärts essen
Hochwertig
Gutes Preis- Leistungs-Verhältnis
Günstig
Hell
Leicht
Nicht sättigend
Populär unter Frauen
Das populärste Bier unter Männern
Das unpopulärste Bier unter Männern
Gleiche Popularität unter Frauen, Unterschied unter Männern
QUESTIONSTAR · Dr. Paul Marx247 / 274
6.4 · WahrnehmungskartenBeziehungen zwischen Eigenschaften
Wahrnehmungskarten
Beziehungen zwischen den Eigenschaften
Je kleiner der Winkel zwischen Eigenschaftsvektoren, desto höher ist deren paarweise Korrelation.
Budget
Hochwertig
Stark
Leicht
Arbeiter
Vollmundig
Stark
Populär unter Männern
Zum besonderen Anlass
Auswärts essen
Hochwertig
Gutes Preis- Leistungs-Verhältnis
Günstig
Hell
Leicht
Nicht sättigend
Populär unter Frauen
Gleiche Popularität unter Männern, starker Unterschied unter Frauen
Gleiche Popularität unter Frauen, Unterschied unter Männern
Die unter Männern populären Marken neigen dazu, stark zu sein
Rechter Winkel ⇒ Popularität unter Männern sagt nichts über Popularität unter Frauen aus
Welche Medikamente stehen unter stärkster Konkurrenz?Tylenol und Motrin (am nächsten zueinander)
Eine Eigenschaft zur besten Beschreibung?„Sanft" — am weitesten vom Ursprung entlang dieses Vektors
Welche zwei Eigenschaften kommunizieren die Vorzüge am besten?„Sanft" und „Effektivität" (die längsten Vektoren)
Höherer Preis, weil sanfter als alle anderen?Nein! In der Wahrnehmung sind diese Eigenschaften unabhängig voneinander.
Welche Eigenschaft (außer „Gut für Kinder") zuerst optimieren?„Hart zu schlucken" — kleinster Winkel zu „Gut für Kinder".
Sanft
Fairer Preis
Gut für Kinder
Hart zu schlucken
Lange Wirkung
Effektivität
QUESTIONSTAR · Dr. Paul Marx253 / 274
6.4 · WahrnehmungskartenLebensmittel
Wichtigkeit der Wahrnehmung in Positionierung
Kurioser aber typischer Fall
40 Lebensmittel: subjektive Wahrnehmung vs. objektive Eigenschaften.
QUESTIONSTAR · Dr. Paul Marx254 / 274
6.4 · WahrnehmungskartenLebensmittel · Fazit
Wichtigkeit der Wahrnehmung in Positionierung
Kurioser aber typischer Fall
40 Lebensmittel: subjektive Wahrnehmung vs. objektive Eigenschaften.
Die Wahrnehmung bzw. Bewertung vieler Lebensmitteleigenschaften hat oft nichts oder sehr wenig mit dem realen Gehalt dieser Eigenschaften zu tun.
QUESTIONSTAR · Dr. Paul Marx255 / 274
Kapitel 7Kapitelübersicht
7
Kapitel
Ergebnisse berichten
Berichterstellung & Präsentation — Stufe 6 des Forschungsprozesses
Manager sollen den Bericht leicht verstehen, den Ergebnissen vertrauen und wissen, welche Maßnahmen sie ergreifen sollten.
QUESTIONSTAR · Dr. Paul Marx256 / 274
Kapitel 7 · Ergebnisse berichtenEinordnung
Die letzte Stufe des Forschungsprozesses
1Problemdefinition
›
2Forschungsansatz
›
3Forschungsdesign
›
4Feldarbeit / Datenerhebung
›
5Datenaufbereitung & Analyse
›
6Bericht & Präsentation
Letzter Schritt
Der Bericht ist der am häufigsten unterschätzte Schritt des Forschungsprozesses.
Voller Wert oder verloren
Selbst eine methodisch perfekte Studie verliert ihren Wert, wenn die Ergebnisse schlecht vermittelt werden.
Ziel
Ergebnisse so darstellen, dass sie unmittelbar in die Entscheidung einfließen — nicht nur zusammenfassen, sondern interpretieren.
QUESTIONSTAR · Dr. Paul Marx257 / 274
Kapitel 7 · Ergebnisse berichtenBedeutung
Warum Bericht und Präsentation zählen
Greifbares Produkt
Nach Projektende bleibt oft nur der schriftliche Bericht — er dient als historischer Beleg der gesamten Studie.
Entscheidungsgrundlage
Die Managemententscheidung stützt sich auf den Bericht. Ein schwacher Abschluss entwertet die gesamte vorausgegangene Forschung.
Einziger Berührungspunkt
Viele Manager erleben nur Bericht und Vortrag — und bewerten daran die Qualität des gesamten Projekts.
Basis für Folgeaufträge
Die Entscheidung für künftige Forschung oder denselben Dienstleister hängt am wahrgenommenen Nutzen.
QUESTIONSTAR · Dr. Paul Marx258 / 274
Kapitel 7 · Ergebnisse berichtenProzess
Vom Datenergebnis zum Follow-up
Interpretation der Datenanalyse
›
Schlussfolgerungen & Empfehlungen
›
Berichterstellung
›
Mündliche Präsentation
›
Lektüre durch den Auftraggeber
›
Research Follow-up
Interpretieren statt zusammenfassen
Die Ergebnisse sollen direkt als Input in die Entscheidungsfindung dienen; wo sinnvoll, werden Schlüsse gezogen und umsetzbare Empfehlungen gegeben.
Vorab abstimmen
Kernergebnisse, Schlüsse und Empfehlungen vor dem Schreiben mit den Entscheidungsträgern besprechen — das sichert Passung, Akzeptanz und Liefertermine.
Übergibt den Bericht, fasst die Projekterfahrung zusammen (ohne Ergebnisse) und weist auf nötige Folgeschritte hin.
Titelblatt
Titel im Manager-Ton statt »Research-Speak«; Angaben zu Forscher und Auftraggeber, Datum.
Inhaltsverzeichnis
Haupt- und Unterüberschriften mit Seitenzahlen; danach Verzeichnisse für Tabellen, Grafiken, Anhänge.
Executive Summary
Oft der einzige Teil, den die Geschäftsleitung liest.
Beschreibt knapp Problem, Ansatz und Design und widmet einen Abschnitt den zentralen Ergebnissen, Schlüssen und Empfehlungen. Wird zuletzt geschrieben — erst wenn der gesamte Bericht steht.
QUESTIONSTAR · Dr. Paul Marx261 / 274
Kapitel 7 · BerichtsformatHaupt- & Schlussteil
Der inhaltliche Kern
1
Problemdefinition
Hintergrund, Gespräche mit Entscheidern und Experten, dann klare Management- und Forschungsfrage.
2
Ansatz & Design
Theoretische Grundlagen, Modelle, Hypothesen; Methoden grafisch und nicht-technisch, Details in den Anhang.
3
Datenanalyse
Analyseplan und -techniken begründen, in einfachen Begriffen mit Beispielen erklären.
4
Ergebnisse
Längster Teil. Gliederung nach Analyseform, Erhebungsmethode oder Zielen — an den Informationsbedarf gekoppelt.
5
Schlussfolgerungen & Empfehlungen
Nicht bloß zusammenfassen: interpretieren und — wenn möglich — umsetzbare Empfehlungen ableiten.
6
Limitationen & Anhang
Grenzen ausgewogen benennen, ohne Vertrauen zu untergraben; Anhang mit Autorisierung, Fragebogen, Stichprobe.
QUESTIONSTAR · Dr. Paul Marx262 / 274
Kapitel 7 · BerichtsschreibenGrundsätze
Grundsätze guten Schreibens
Leserorientiert
Für die Entscheider schreiben; Fachjargon vermeiden, technische Begriffe in den Anhang.
Leicht zu folgen
Logische Struktur, Überschriften, kurze klare Sätze; von Außenstehenden gegenlesen lassen.
Professionell
Sorgfältige Gestaltung; Typografie variieren — aber nur so weit, wie es das Verständnis stützt.
Objektiv
Design, Ergebnisse und Schlüsse korrekt darstellen, nicht den Erwartungen des Managements anpassen.
Text ↔ Grafik
Schlüsselinfos mit Tabellen/Grafiken verstärken — und Grafiken mit Zitaten zum Leben erwecken.
Prägnant
Alles Unnötige weglassen — Kürze jedoch nie auf Kosten der Vollständigkeit.
»Die Leser Ihrer Berichte sind beschäftigte Menschen — kaum jemand kann Bericht, Kaffee und Wörterbuch gleichzeitig balancieren.«
QUESTIONSTAR · Dr. Paul Marx263 / 274
Kapitel 7 · VisualisierungTabellen
Richtlinien für Tabellen
Nummer & Titel — eindeutige arabische Nummer, kurzer beschreibender Titel, im Text referenzierbar.
Anordnung der Daten — nach dem wichtigsten Aspekt ordnen: Zeit, Größenordnung oder alphabetisch.
Maßeinheit — Basis klar angeben (Spalten- vs. Zeilenprozente, Stichprobengröße).
Lesehilfen — Linien, Schattierung oder Weißraum führen das Auge über die Zeile.
Quelle: GlobalCash-Europe98, Statistical Report for Europe, S. 137
QUESTIONSTAR · Dr. Paul Marx264 / 274
Kapitel 7 · VisualisierungGrafiktypen
Grafiktypen im Überblick
Karten
Geo- und Positionierungskarten zeigen Standorte, Kunden, Wettbewerber — Basis der Geodemografie.
Kreis- / Tortendiagramm
Einfache relative Häufigkeiten. Nicht für Zeitverläufe oder mehrere Variablen.
Liniendiagramm
Verbindet Datenpunkte — ideal für Trends über die Zeit; mehrere Reihen vergleichbar.
Balken / Histogramm
Zeigt absolute/relative Größen und Differenzen. Histogramm = vertikale Häufigkeiten.
Gestapelt / gruppiert
Wenige Datenpunkte, um Unterschiede zwischen Gruppen qualitativ darzustellen.
Schaubilder & Flowcharts
Stellen Prozessschritte oder die Verknüpfung qualitativer Ideen dar.
QUESTIONSTAR · Dr. Paul Marx265 / 274
Kapitel 7 · VisualisierungZwei Regeln
Zwei Regeln, die man nicht vergisst
Kreisdiagramm
max. 7 Segmente
Für einfache relative Häufigkeiten geeignet — nicht für Zeitverläufe oder Beziehungen zwischen mehreren Variablen.
Vorsicht
Keine 3D-Diagramme
3D verzerrt relative Größen und verwirrt das Publikum. Programme bieten viele 3D-Optionen — kaum eine stellt Daten klar und unverzerrt dar.
QUESTIONSTAR · Dr. Paul Marx266 / 274
Kapitel 7 · Mündliche PräsentationDer Vortrag
Der Vortrag prägt den ersten Eindruck
Vorbereitung ist alles
Skript/Outline nach dem Bericht, mehrfach proben.
Aufs Publikum zuschneiden
Hintergrund, Interesse und Betroffenheit der Zuhörer kennen.
Visuelle Medien
Flipchart, Projektor, Software — die Botschaft nie aus dem Blick verlieren.
Körpersprache & Stimme
Gestik, Blickkontakt, Lautstärke und Tempo variieren; starker Schluss.
»My paradigm is the guitar.« Technik ist nur Werkzeug — die gute Gitarre allein trägt den Auftritt nicht. Sie tun es.»Predictability precedes boredom.«
QUESTIONSTAR · Dr. Paul Marx267 / 274
Kapitel 7 · Nach der PräsentationFollow-up
Research Follow-up
1
Den Auftraggeber unterstützen
Technische Teile erklären, bei der Umsetzung helfen, Folgeprojekte besprechen und Ergebnisse ins MIS/DSS integrieren.
2
Das Projekt evaluieren
Solange es frisch ist, kritisch fragen: »Hätte man das Projekt effektiver oder effizienter durchführen können?«
Vertrauen als Schlüssel
Die Qualität der persönlichen Interaktion zwischen Manager und Forschendem prägt die wahrgenommene Qualität des Berichts selbst. Vertrauen beeinflusst Beziehungsqualität, Engagement, Bindung — und letztlich, wie stark die Marktforschung tatsächlich genutzt wird.
QUESTIONSTAR · Dr. Paul Marx268 / 274
Kapitel 7 · InternationalLänder & Sprachen
Berichte über Länder und Sprachen hinweg
Mehrere Versionen
Für Management in verschiedenen Ländern und Sprachen eigene, leserspezifische Versionen — inhaltlich vergleichbar, im Format ggf. unterschiedlich.
Kulturelle Sensibilität
Beim Vortrag kulturelle Normen beachten — Humor ist nicht überall angebracht. Empfehlungen ggf. länderspezifisch anpassen.
Praxisbezug
Parallel gepflegte Sprachversionen (z. B. DE / RU / KZ) sind kein Übersetzungs-, sondern ein Berichtsproblem: feldweise Lokalisierung, vergleichbare Kennzahlen, konsistente Begriffe.
QUESTIONSTAR · Dr. Paul Marx269 / 274
Kapitel 7 · EthikIntegrität
Integrität bei Interpretation und Bericht
33%
der befragten Marktforscher nennen Fragen der Forschungsintegrität als ihr schwierigstes ethisches Problem.
Typische Verstöße
Relevante Daten ignorieren
Das Forschungsdesign kompromittieren
Statistiken bewusst missbrauchen
Zahlen fälschen oder Ergebnisse verändern
Ergebnisse zugunsten einer Sichtweise umdeuten
Informationen zurückhalten
Versuchung widerstehen: Aus uneindeutigen Befunden eine »kohärente, wohlgeformte Geschichte« zu formen, ist befriedigend — aber unethisch. Objektivität wahren, auch wenn nichts Signifikantes herauskommt.
QUESTIONSTAR · Dr. Paul Marx270 / 274
Kapitel 7 · Reporting heutePush → Pull
Vom »Push« zum »Pull«
Damals
Gedruckter Bericht, »push«
Passwortgeschützte Intranet-Berichte
Erste Multimedia-Reports im Web
Suchbar, weltweit abrufbar
Heute
Interaktive Dashboards, »pull«
Echtzeit-Daten & Live-Filter
Kreuztabellen und Gewichtung on demand
Verknüpfte Reports, Regeln zur Robustheit
QUESTIONSTAR · Dr. Paul Marx271 / 274
Kapitel 7 · ZusammenfassungTake-aways
Die wichtigsten Take-aways
1
Letzter Schritt, voller Hebel
Bericht und Präsentation entscheiden über den wahrgenommenen Wert der gesamten Studie.
2
Interpretieren, nicht referieren
Ergebnisse als Entscheidungsinput aufbereiten — mit umsetzbaren Empfehlungen.
3
Leser zuerst
Jargon vermeiden, klar strukturieren, Text und Visualisierung gegenseitig stützen.
4
Visualisierung mit Disziplin
≤ 7 Tortensegmente, Vorsicht bei 3D, Tabellen sauber beschriften.
5
Mensch vor Technik
Der Vortrag lebt vom Vortragenden — nicht von der Folie.
6
Integrität & Follow-up
Objektiv bleiben, beim Auftraggeber nachfassen, das eigene Projekt evaluieren.
QUESTIONSTAR · Dr. Paul Marx272 / 274
Grundlagen der UmfrageforschungÜber den Autor
Über den Autor
Dr. Paul Marx war Professor für Marketing an der Universität Siegen, wo er insbesondere zu E-Commerce, Präferenzmessung, Neue Medien, Big Data und Empfehlungssystemen forschte. Er studierte Aero- und Hydrodynamik sowie Management an der Staatlichen Technischen Universität Nowosibirsk (Russland) und bekleidete anschließend leitende Positionen im Marketing. Im Jahr 2000 zog er nach Deutschland, vertiefte sein Studium der Wirtschaftswissenschaften an der Universität Hannover und gründete den Online-Service für Online-Umfragen eQuestionnaire — heute QUESTIONSTAR. Paul promovierte an der Bauhaus-Universität Weimar und veröffentlichte seine Forschung in führenden internationalen Zeitschriften, u. a. im Journal of Marketing.
Backhaus, K., Erichson, B., Plinke, W., Weiber, R. (2015): „Multivariate Analysemethoden: Eine anwendungsorientierte Einführung“, Springer Gabler, 14. Auflage.
Brandt, D. R. (1996): „Secure Customer Index“, Maritz Research.
Bruner, G. C. (2012): „Marketing Scales Handbook“, Vol. 6.
Burke, Inc. — burke.com.
Chuang, S.-C., Chen, H.-C. (2008): International Journal of Design.
Malhotra, N. K. (2020): „Marketing Research: An Applied Orientation“, Prentice Hall, 6th edition.
Marx, P. (1979–2026) — eigene internationale Erfahrung.
Moore, W. L., Pessemier, E. A. (1993), S. 145.
Myers, J. H. (1996): „Segmentation & Positioning for Strategic Marketing Decisions“, South Western Educ. Pub.
Noelle-Neumann, E., Petersen, T. (1998): „Alle, nicht jeder. Einführung in die Methoden der Demoskopie“, Springer, S. 192.
Reichheld, F. (2003): „The One Number You Need to Grow“, Harvard Business Review.
Reichheld, F., Markey, R. (2011): „The Ultimate Question 2.0“, Harvard Business Review Press.
Sullivan III, M. (2010): „Statistics: Informed Decisions Using Data“, Pearson, 3rd edition.
Visocky O'Grady, J. & K. (2009): „The Information Design Handbook“, HOW Books.
Course „Statistics I“ of Elgin Community College.
Lizenz & Haftungsausschluss
Haftungsausschluss: Der Autor sowie affiliierte Personen/Organisationen können für die Verletzung jeglicher Lizenzbedingungen nicht verantwortlich gemacht werden, sofern diese nicht durch ihr aktives Tun verursacht wurden. Markennamen und geschützte Warenzeichen sind Eigentum ihrer jeweiligen Inhaber und werden lediglich beschreibend genannt. Irrtümer vorbehalten.
CC BY-NC-SA 3.0
Diese Präsentation unterliegt der Creative-Commons-Attribution-NonCommercial-ShareAlike-Lizenz, soweit nicht anders angegeben. Jede Nutzung oder Verbreitung erfordert einen Verweis auf diese Präsentation und die explizite Nennung von Dr. Paul Marx und QUESTIONSTAR.

 ZielWahrheit
Literaturrecherche
Befragung
Interview
ZielWahrheit
Literaturrecherche
Befragung
Interview






 Apfel
Apfel Tomate
Tomate Orange
Orange



 Kiwi
Kiwi Banane
Banane Erdbeere
Erdbeere
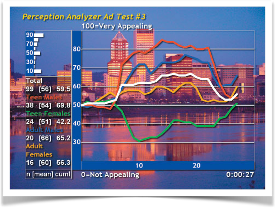

 Sehr zufrieden
Werde definitiv wieder nutzen
Werde definitiv weiterempfehlen
Secure Customer
Sehr zufrieden
Werde definitiv wieder nutzen
Werde definitiv weiterempfehlen
Secure Customer
 Quelle: Burke Inc. · http://www.burke.com/
Quelle: Burke Inc. · http://www.burke.com/





















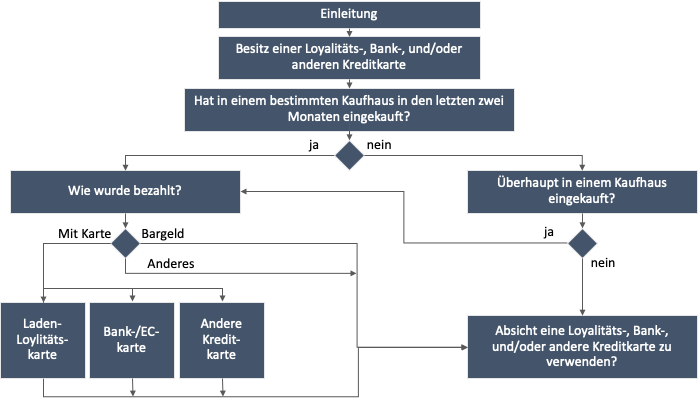







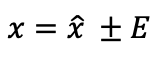
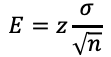
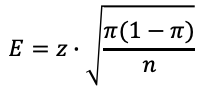


 Maximal bei π = 0,5
Maximal bei π = 0,5
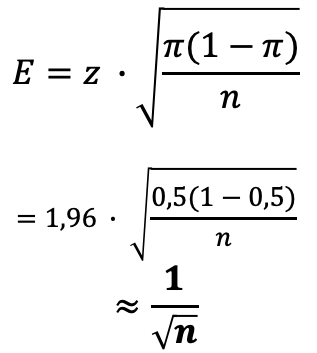
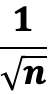

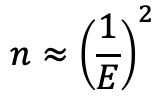 nkorr=n · Nn + N − 1
nkorr=n · Nn + N − 1
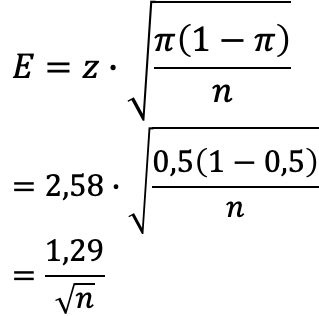
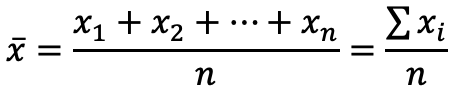
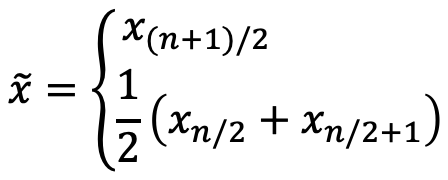 für ungerade nfür gerade n
für ungerade nfür gerade n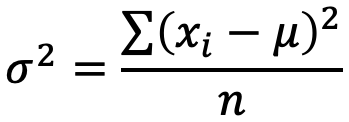
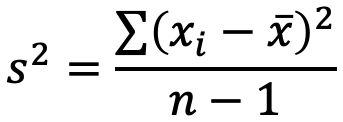
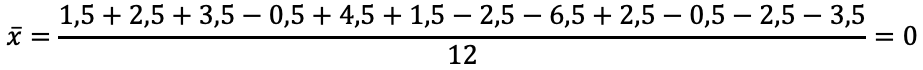
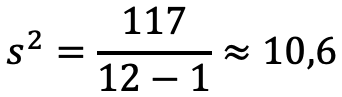
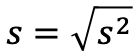
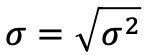
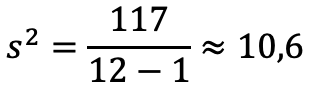 Quadratzoll
Quadratzoll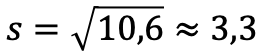 Zoll
Zoll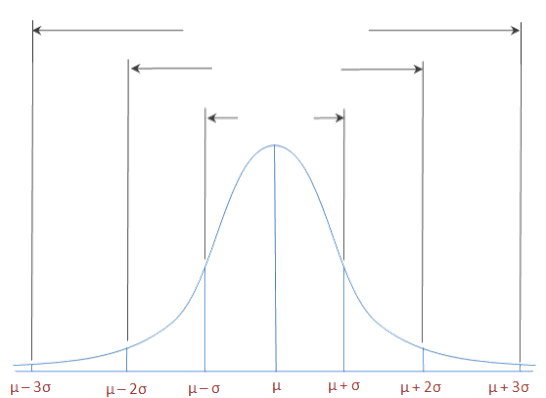
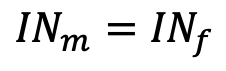
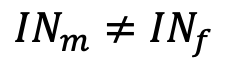
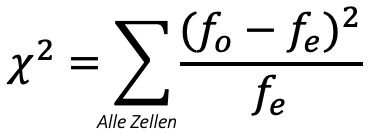
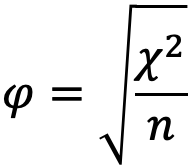
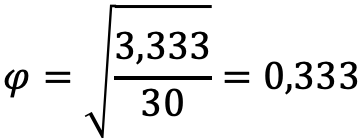
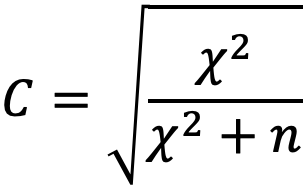
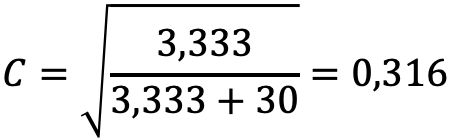
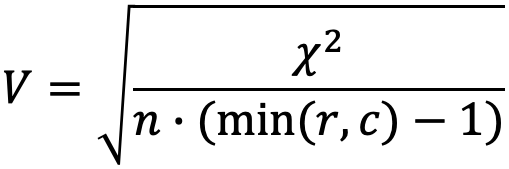
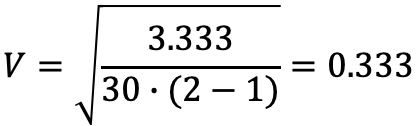
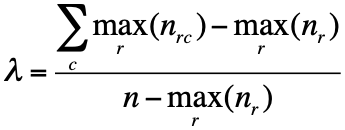
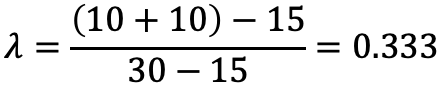
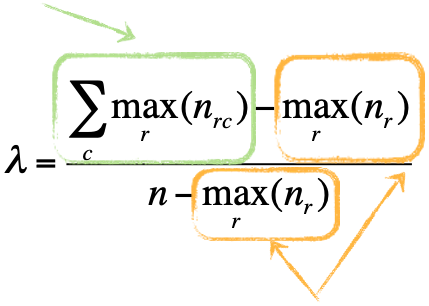
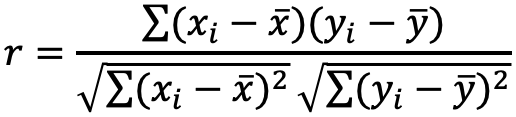
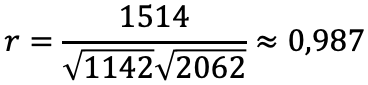

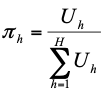
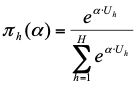








 »Die Leser Ihrer Berichte sind beschäftigte Menschen — kaum jemand kann Bericht, Kaffee und Wörterbuch gleichzeitig balancieren.«
»Die Leser Ihrer Berichte sind beschäftigte Menschen — kaum jemand kann Bericht, Kaffee und Wörterbuch gleichzeitig balancieren.«